With version 6.1 we added a new to create custom hierarchies in some dimensions, including Sprints.
You would like to import custom properties for sprints to represent a potential grouping mechanism. For example, you can import a property cycle for Sprints with additional data import.
Then you can use this custom property Cycle to build a new custom hierarchy in Sprint dimension and group sprints by cycles dynamically.
Import additional property to Sprint based on Sprint naming pattern XX Sprint # and you would like to retrieve the Sprint # only from it.
REST API source definition
{
"application_type": "rest_api",
"application_params": {
"source_params": {
"url": "https://ecosystem.atlassian.net/rest/agile/1.0/board?type=scrum",
"pagination": "offset_limit",
"incremental": null,
"incremental_stop_import": null,
"authentication_type": "basic",
"username": "specify username",
"content_type": "json",
"custom_javascript_code": "// retrieves all sprints within one board and will go from the last sprint and rank decreasingly closed sprints\nvar sprints = [{\n sprint_id: null,\n sprint_name: null \n}];\nvar allSprints = [];\nvar allSprintsLoaded = false;\nstartAt = 0;\nmaxResult = 50;\nif (doc.type == \"scrum\") {\n\n do \n {\n result = getDocument( \"/rest/agile/1.0/board/\" + doc.id + \"/sprint?startAt=\" + startAt + \"&maxResults=\" + maxResult, {ignoreErrors: \"404\"});\n if (result && result.values ) {\n allSprints = allSprints.concat(result.values);\n allSprintsLoaded = result.isLast;\n startAt = startAt + maxResult;\n }\n }\n while (!allSprintsLoaded); \n \n if (allSprints ) { \n for(var i = 0; i < allSprints.length; i++) {\n var sprint = allSprints[i];\n if (sprint && sprint.originBoardId == doc.id ) {\n sprints.push({\n sprint_id: sprint.id,\n sprint_name: sprint.name.match(/( Sprint )(\\d+)/) ? sprint.name.match(/( Sprint )(\\d+)/)[0] : doc.name\n });\n }\n }\n} \n\n}\nreturn _.uniq(sprints);",
"json_data_path": "$.values",
"offset_parameter": "startAt",
"limit_parameter": "maxResults",
"limit_value": 50
},
"extra_options": {
"regular_import_frequency": null,
"regular_import_at": "",
"time_zone": "Helsinki"
}
},
"source_cube_name": "Issues",
"columns": [
{
"name": "sprint_id",
"data_type": "integer",
"dimension": "Sprint",
"dimension_level": "Sprint",
"key_column": true,
"skip_missing": true
},
{
"name": "sprint_name",
"data_type": "string",
"dimension": "Sprint",
"dimension_level": "Sprint",
"property": "Cycle"
}
]
}
In Source Data tab add new source application and in Import definition use the REST API source definition added above.
Update the Source data URL by a correct JIRA HOME URL/Jira site URL instead of https://ecosystem.atlassian.net:

Add the authentication to your Jira.
If you have a different Sprint naming pattern you would like to use, update the JavaScript code by edit custom javascript code.
The current JavaScript calculation should retrieve the Sprint # from sprints with a naming pattern XX Sprint #. The mapping is in place as well to import a property for a sprint dimension with a name Cycle. Run an import.
After import, you can add custom hierarchy in Sprint dimension based on the Property Cycle.
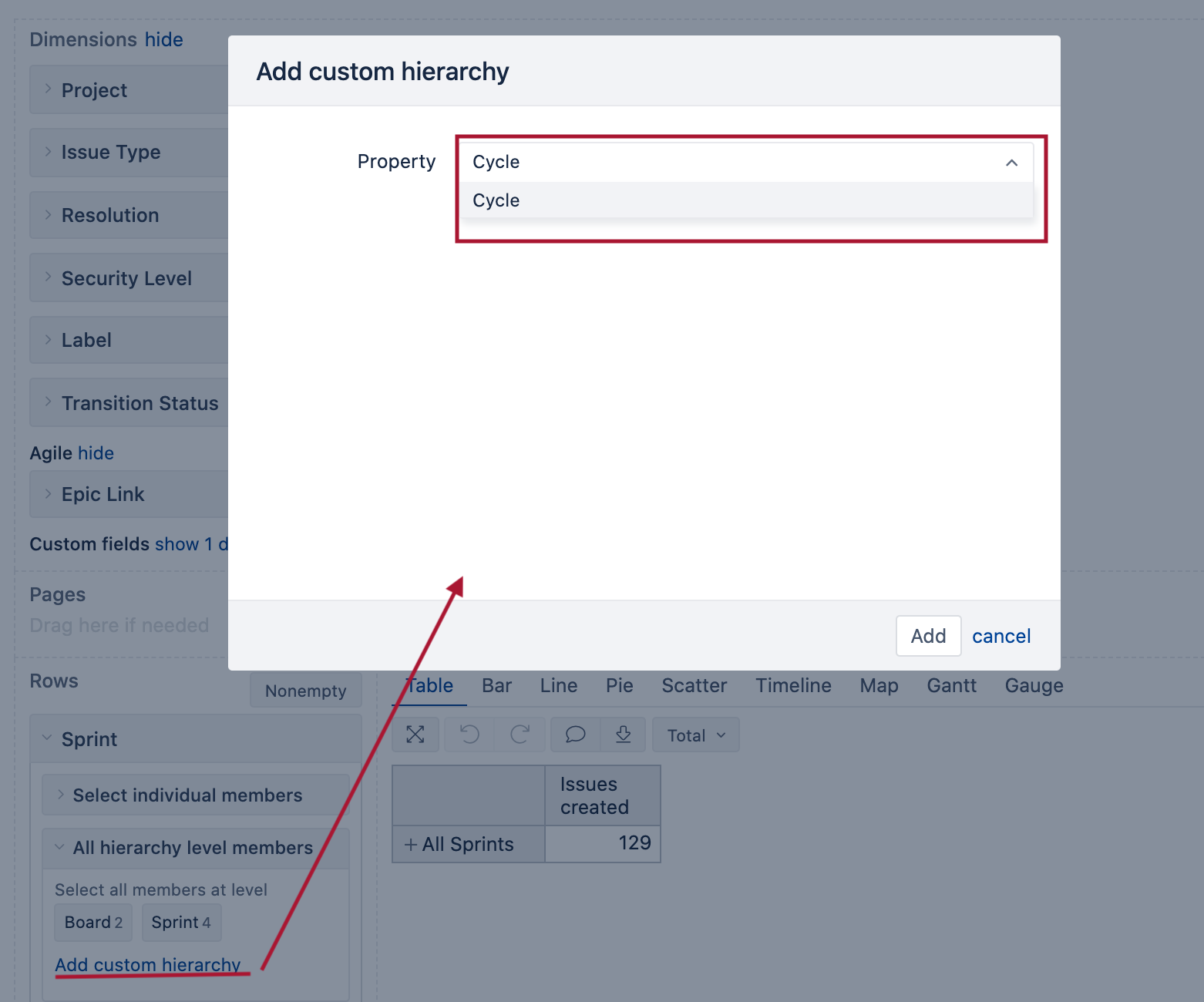
Then you can use this new Sprint cycle hierarchy in the report. You might want to reorder the members there, though. You can define a new custom report specific measure (as it is needed in a particular report only):
Sprint number:
Cast(Replace( ExtractString([Sprint].CurrentHierarchyMember.Name , 'Sprint (\d+).*'), "Sprint " , "") as Numeric)
Then you can use this measure to the report and apply the Ascending order to it.
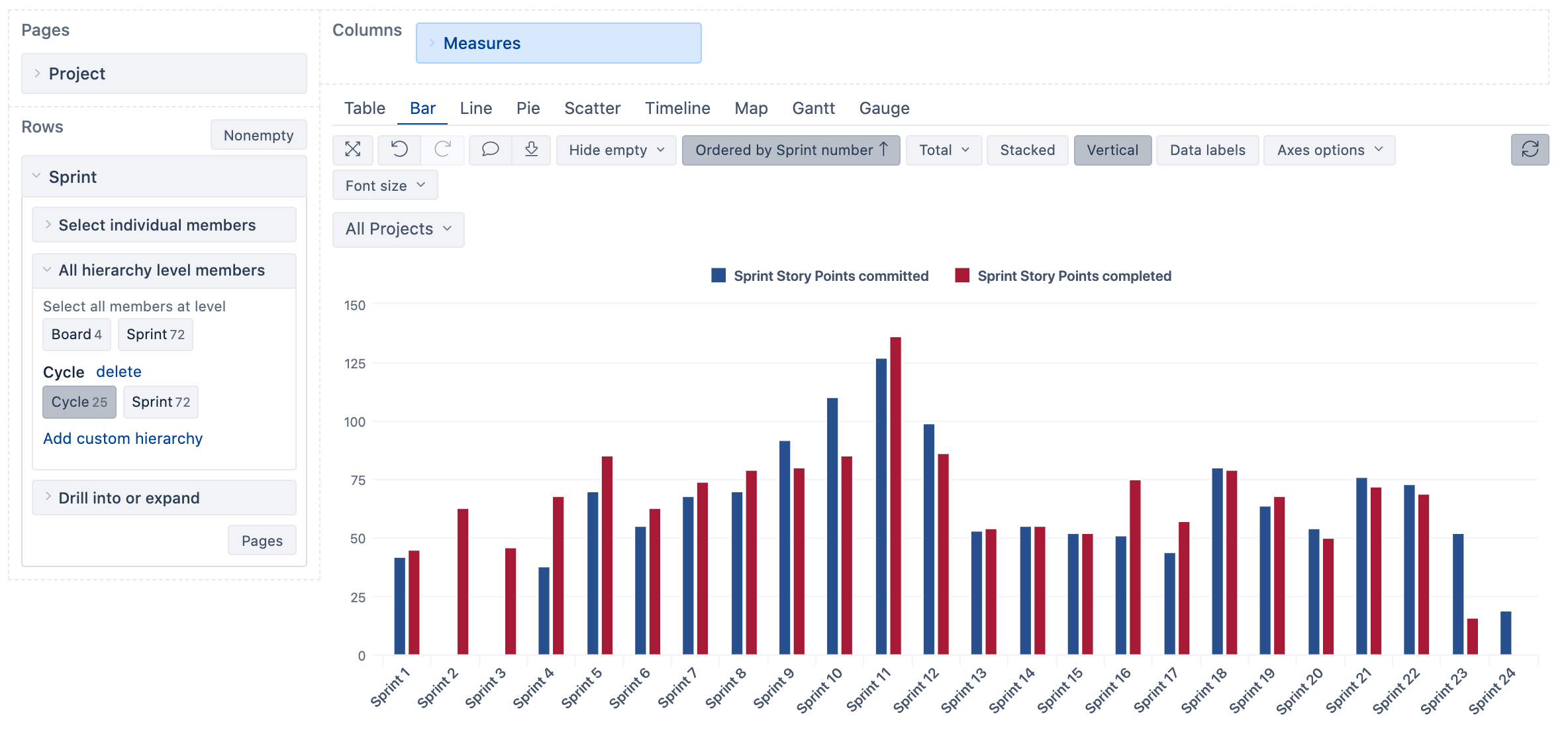
Here are several reports in eazyBI Demo Training account created based on this custom hierarchy.:
Sprints by sprint name balance
Sprint by sprint name velocity
Sprints by name current cycle story points burn-down
Daina / support@eazybi.com