I’m trying to import a CSV and associate it with some Jira information. So that I can combine non-labour and labour costs for a Jira “initiative” (we use the term “Solution”).
Currently i am importing the labour costs through EazyBI using its support for Tempo Timesheets. So that part is done.
What i’m trying to do now is combine the CSV of non-labour costs.
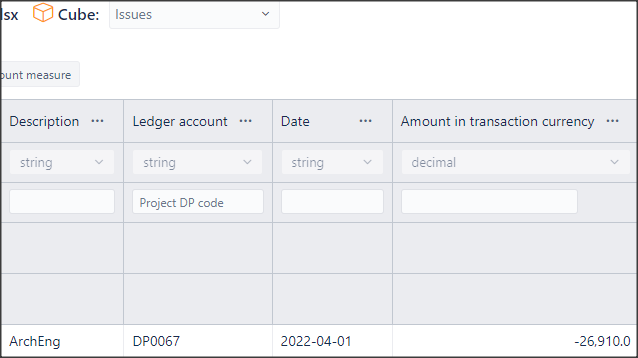
What i have tried to do is add a custom field to the Jira Initiative/Solution called “Project DP code”, i am importing this as a dimension. This is a string of the form “DP0067” , “DP0071”, etc.
In the CSV file I have the following (there are other columns too, but they’re not relevant):
DP code Amount Date
DP0067 -26900 2022-04-01
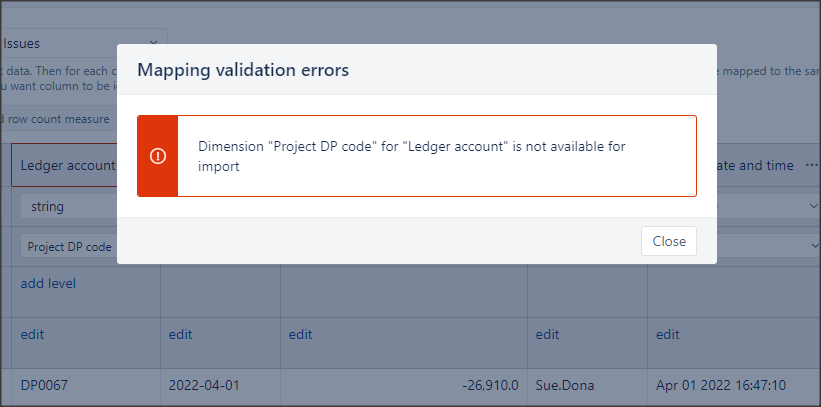
I have tried to set the DP code as using the custom field i defined “Project DP code”, to try to associate it all together but seem to have got something wrong.
Any suggestions for what I could do to resolve this? Or alternative methods?
Hi @CamNZ ,
The error message suggests that you could not select the dimension from the list but typed the dimension name manually.
You can only map the additional data to a single value custom field dimension with one level.
You might read more about that here - Additional data import into Jira Issues cube.
You might add extra settings to finetune this dimension in the eazyBI advanced settings.
After changing the advanced settings for the custom field, please rebuild the dimension by a double import. First, deselect the field from import and launch import to clear the dimension data, and then re-add the field for import and launch another import to rebuild the dimension.
Then you should be able to select this dimension for the additional data mapping.
Regards,
Oskars / support@eazyBI.com
I did have the “dimension = true” set in the advanced settings, but needed to add the “separate_table = true”. This seems to have let me bring the values in, which is a good start!
I have tried the above and added the “separate_table = true” in advanced settings which allows me to choose the field as a dimension in the csv import, but seems the values from the csv are not actually overwriting the original Jira values.