Hi everyone,
I’m trying to build a report that shows how many issues there were in a sprint without SP at closing, not counting the sub-tasks and spikes. Could anyone help me define a measure for such a report?
Thanks in advance,
Zalina
Hi everyone,
I’m trying to build a report that shows how many issues there were in a sprint without SP at closing, not counting the sub-tasks and spikes. Could anyone help me define a measure for such a report?
Thanks in advance,
Zalina
eazyBI offers a measure to show which issues were in Sprint at closing, “Sprint issues at closing”, and also a measure showing how many story points were in Sprint at closing, “Sprint Story Points at closing”. To get the combined view of how many issues were without Stroy points, yuo should create a new calcauted measures.
The calcaution would iterate through all issues that were in Sprint at closing and check their Story Point value on that date.
Sum(
--set of issues
Filter(
--iterate through Parent issues that have been in some sprint
Descendants([Issue.Sub-task].CurrentHierarchyMember,[Issue.Sub-task].[Parent]),
CoalesceEmpty([Measures].[Issue Sprints],"") MATCHES
".*" || [Sprint].CurrentHierarchyMember.GetCaption || ".*"
),
CASE WHEN --issue was in Sprint at Closing but had no SP
[Measures].[Sprint issues at closing] > 0 AND
IsEmpty([Measures].[Sprint Story Points at closing])
THEN --count parent issue
1
END
)
More details on calculated measures and used MDX functions are described here:
Best,
Zane / support@eazyBI.com
Hi Zane!
Thank you so much for you help.
For some reason this measure does not return any results, what could be the issue? I added Project and Sprints in the rows, maybe something else is missing?
Kind regards,
Zalina
The calcaution is designed to work when individual Sprints are on report rows and compares the selected sprint name on report rows with the sprint names for each issue.
If you use vacated members in the Sprint dimension or board level, then you might use a more universal expression:
Sum(
--set of issues
Filter(
--iterate through Parent issues except for Sub-tasks
Descendants([Issue.Sub-task].CurrentHierarchyMember,[Issue.Sub-task].[Parent]),
[Measures].[Issue type] NOT MATCHES "Sub-task"
),
CASE WHEN --issue was in Sprint at Closing but had no SP
[Measures].[Sprint issues at closing] > 0 AND
IsEmpty([Measures].[Sprint Story Points at closing])
THEN --count parent issue
1
END
)
Let me know how this works for you.
Kind regards,
hi @zane.baranovska
when I use your measure
Sum(
--set of issues
Filter(
--iterate through Parent issues that have been in some sprint
Descendants([Issue.Sub-task].CurrentHierarchyMember,[Issue.Sub-task].[Parent]),
CoalesceEmpty([Measures].[Issue Sprints],"") MATCHES
".*" || [Sprint].CurrentHierarchyMember.GetCaption || ".*"
),
CASE WHEN --issue was in Sprint at Closing but had no SP
[Measures].[Sprint issues at closing] > 0 AND
IsEmpty([Measures].[Sprint Story Points at closing])
THEN --count parent issue
1
END
)
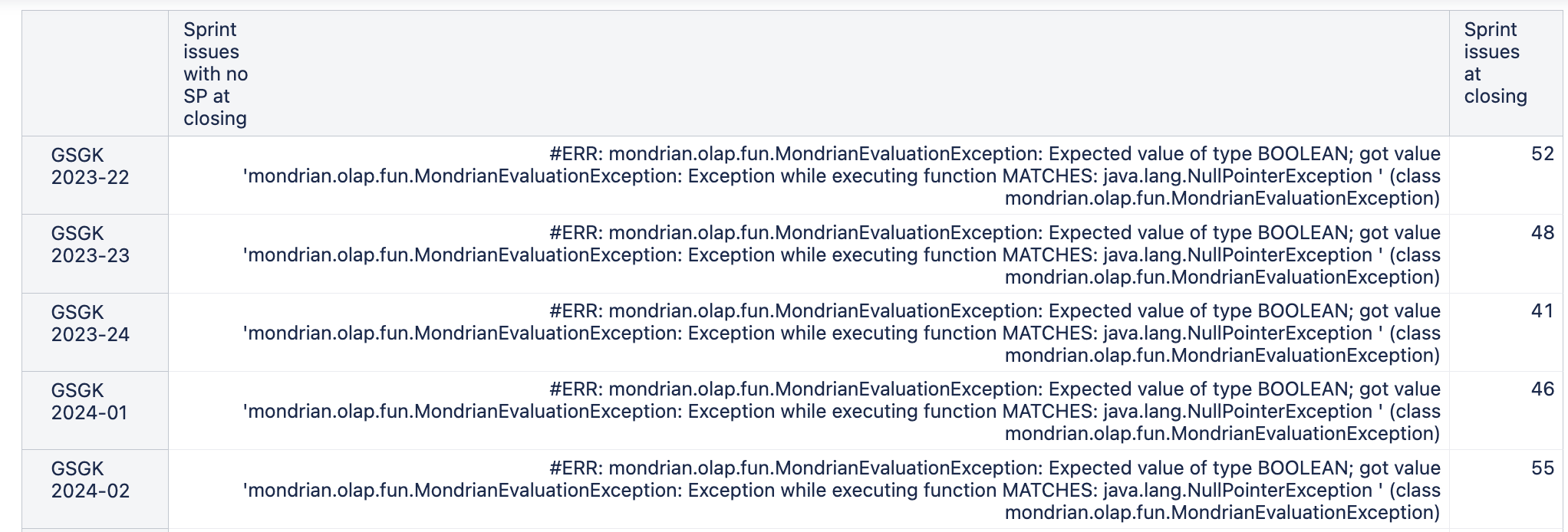
I sometimes get an error, in short:
#ERR: mondrian.olap.fun.MondrianEvaluationException: Expected value of type BOOLEAN; got value 'mondrian.olap.fun.MondrianEvaluationException: Exception while executing function MATCHES: java.util.regex.PatternSyntaxException: Illegal character range near index 21 . * TOP 2023-22 [21nov-05dic] . *
is that because of the string format of my sprint names (i.e the square brackets)?
regards.
Hi @Mauro_Bennici,
The filtering by Sprint name that contains special characters is not applicable in the same way without treating those special characters.
You might want to use a second expression without additional filtering by issue-assigned sprint names:
hi @zane.baranovska ,
does this still work at sprint level?
regards.
The filter by sprint name CoalesceEmpty([Measures].[Issue Sprints],"") MATCHES ".*" || [Sprint].CurrentHierarchyMember.GetCaption || ".*" was added to increase the calcaution performance slightly, but it is not mandatory.
Yes, the calcaution will still filter issues by sprints correctly. The measure “Sprint issues at closing” knows which issues belong to which sprint and validation [Measures].[Sprint issues at closing] > 0 ensures that calculation looks only to issues in the selected sprint.
sorry @zane.baranovska but I get a nullpointer exception with the second formula…
#ERR: mondrian.olap.fun.MondrianEvaluationException: Expected value of type BOOLEAN; got value 'mondrian.olap.fun.MondrianEvaluationException: Exception while executing function MATCHES: java.lang.NullPointerException ’ (class mondrian.olap.fun.MondrianEvaluationException)
@Mauro_Bennici I can not reproduce such an error with this expression. The expression should be built in the Measures (not other dimensions), and the measure formatting should remain default or set to integer.
The report setup as you described (individual sprints on rows and calculated measure on columns) and a code from this community thread work as expected on eazyBI Cloud and the latest version for Jira Data Center 7.1.2.
If you run eazyBI on Jira Data Center, update eazyBI app to the lates version.
If you run eazyBI on Jira Cloud (domain name contains .atlassian.net), you may contact the eazyBI Support and provide details on the account and the report.
@zane.baranovska I took a look at the changelog and saw nothing related to the MATCHES function.
Anyway I replaced NOT MATCHES with <> and it worked just fine.
thanks.