Hello -
I’m trying to solve two problems, one period and the other more effectively.
#1. I’m trying to extract the number of times a string such as “MEO-” appears in a list of linked issues. I created this custom dimension and no matter what I try I am unable to just do a simple "Count number of MATCHES of the word “MEO-”. I’ve gotten around it by doing a length count and a replace to do a diff on, but that just seems incredibly sloppy. (Though it was recommended by someone to “count the commas” to determine number of linked issues, which is what got me there)
Custom Dimension for Linked Issues:
[jira.customfield_linked_issues]
name = "Linked Issues"
outward_link = ["relates to"]
dimension = true
split_by = ","
#2 From that dataset, I’m trying to figure out how many of those have failed against the number of created issues. A metric of average number of linked issues, per issue.
I’m able to get the total of the #1 issue by adding --annotations.total=sum to the calculated measure, (otherwise it displays 0 when it should display, say, 68).
I cannot however get the total field to do the math to calculate the average. It either displays the sum (due to --annotations.total=sum), or 0. I tried --annotations.total=average/avg, but that did not work.
I’m seeing some stuff related to $total-aggregate, but nothing that’s making a lot of sense.
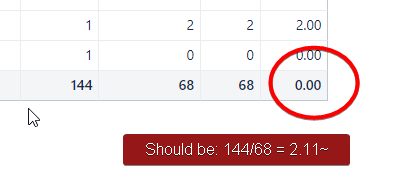
Oh and last thing… even though the dataset of the dimension is broken by commas, “split_by = “,”” doesnt seem to be doing anything? The cell still says, ISSUE-1, ISSUE-2, ISSUE-3, MEO-2, ISSUE-5… etc. What does the split do exactly? Multiple values doesn’t seem to do much either