Here are two possible solutions you can consider here.
- Define calculated members for each PI. You can create calculated Sprint dimension members using function Aggregate and listing sprints for each PI or use a filter by Sprint start date between a PI start and end date.
Here is an example formula for 19P3 (using period 01 DEC 2019 and 29 FEB 2020):
Aggregate(Filter(
[Sprint].[Sprint].Members,
DateBetween(
[Sprint].CurrentMember.Get("Start date"),
"01 DEC 2019" , "29 FEB 2020"
)
))
You can define calculated members for any PI period and then add them manually to reports.
- With version 6.1. (and on the cloud) we have an option to build custom hierarchies based on some sprint properties imported with additional data import. You can define an excel or csv file (as a mockup) and import additional property for a sprint representing the PI.
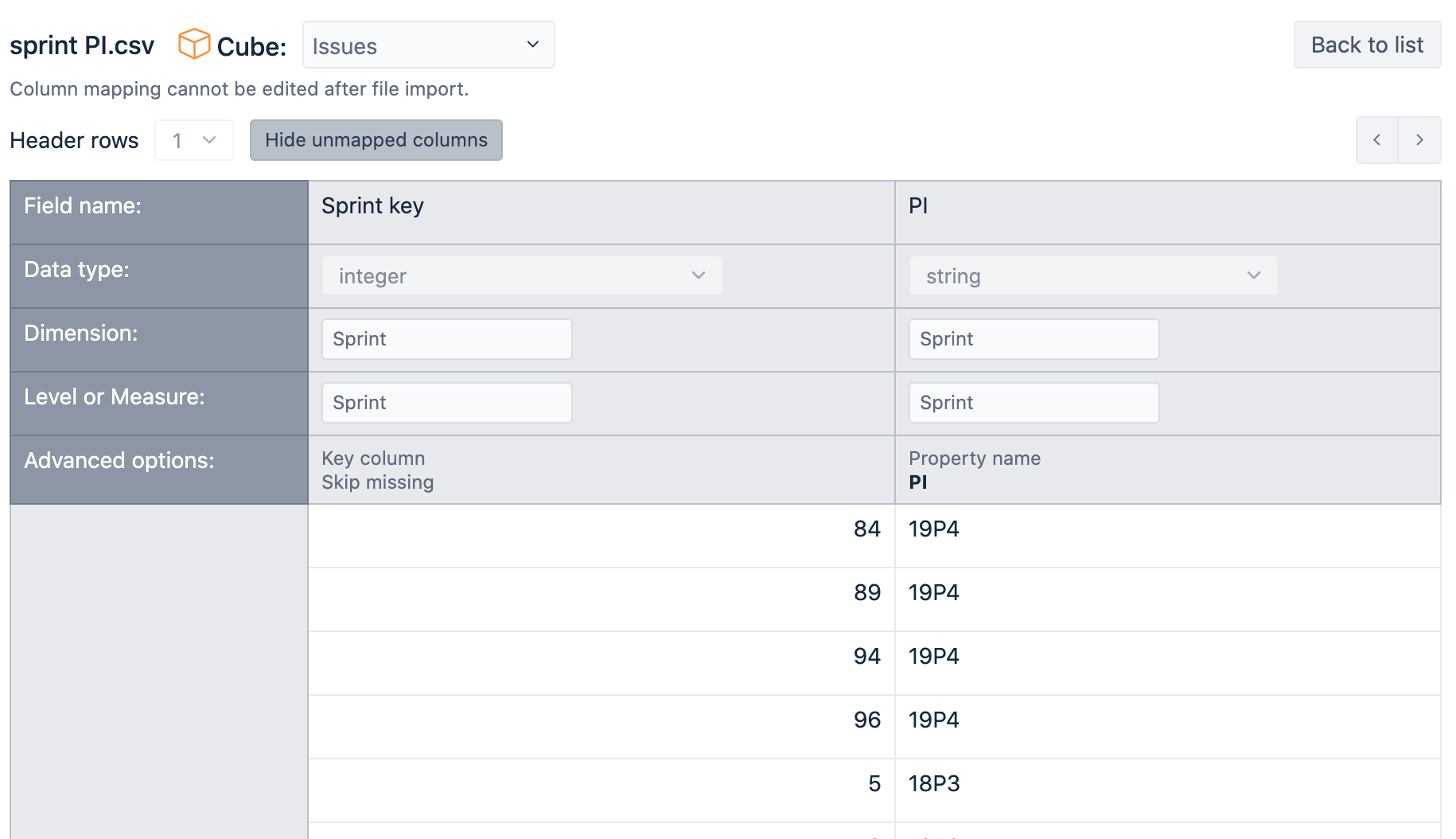
I used a file with Sprint key in one column and PI name in another one:
I used mapping by Key column with option Skip missing for Sprint key column and mapped PI as a property for a sprint.
Then I defined a new custom hierarchy using this PI property:
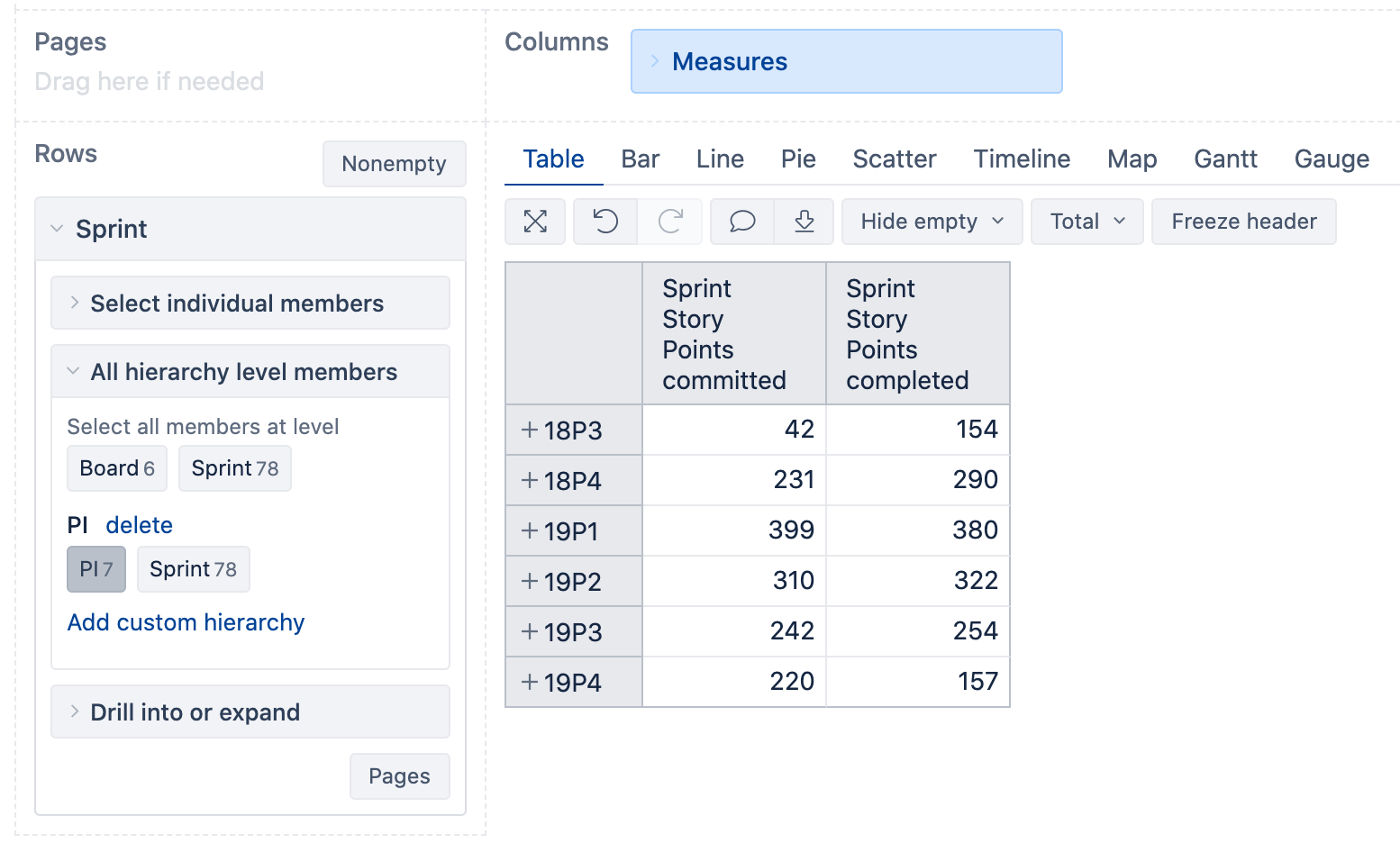
This setup will work faster for Jira instances with many sprints, and reports will update automatically whenever you upload a new file with PI names for sprints.
As an additional option here, you can consider automating PI import using REST API import. Here is a community topic you can check out on how to access Sprints with REST API and define some additional sprints’ properties. You can use the REST API source as a basis and update the JavaScript code by calculating PI property based on some rules:
Daina / support@eazybi.com