HI all:
I’m quite new to Jira and EazyBI (and I’m not getting time to read the manuals) and I need help with this. We need to calculate the average time spent by incidents in some statuses, in particular in the To Do category of statuses because we want to measure the wait time of the tickets (in contrast to the time the ticket is being worked on)
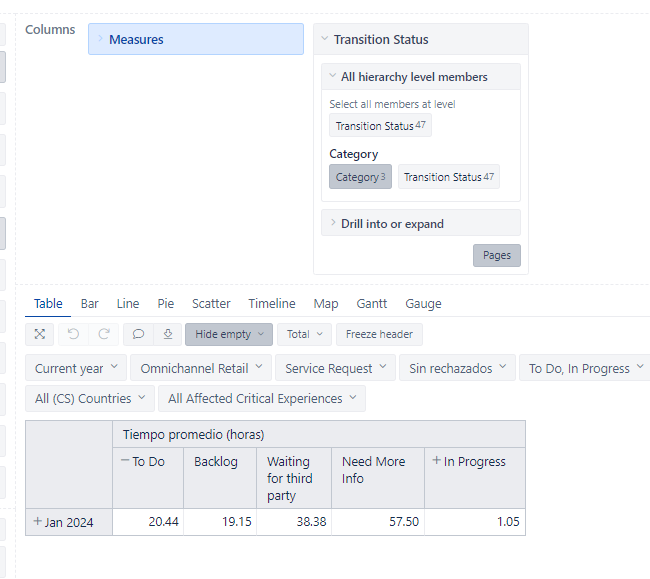
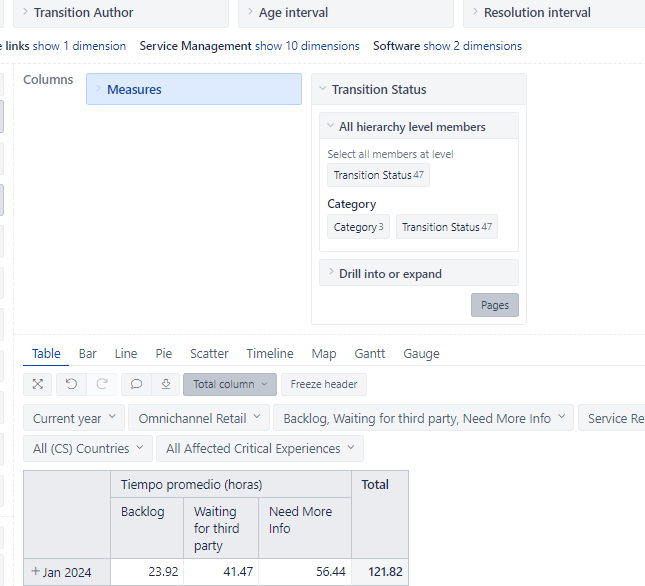
I started using the [Average days in transition status], adapted to measure hours
CASE WHEN [Measures].[Transitions from status] > 0 THEN
[Measures].[Days in transition status] * 24 /
[Measures].[Transitions from status]
END
When I use that measure in 2 different reports, I get 2 different results
When using category transition status (forget the In progress column)
When I use specific transition statuses
What we want to know is how much time (in average) the issues are “waiting” , so I believe the secound one is a more accurate measure, but after reading some forums (one example below) I’m not sure of anything 
Can someone please enlighten me on this?
Thanks
Lead and Cycle Time in eazyBI (atlassian.com)
Hi, @walterdp
Welcome to the eazyBI community! You are not alone.
Did you know eazyBI supports defining and importing cycles based on issue statuses? Based on your requirements, I feel this is the way you should go!
First, you define the cycle - in your case, all the statuses that are “waiting”.
Perform the import.
And use the new cycle measures in the reports.
Please read more here on our documentation page: Issue cycles
Or You can start by watching my collages Elita’s training video about this topic here: Training videos on specific topics)
Issue cycles allow you to group statuses based on your requirements and create one issue Cycle. eazyBI would automatically create several measures, including the average days the issue spent in the cycle.
Let me know how it went.
Kindly,
Ilze
HI @ilze.mezite ,
Thanks for replying! I’ll try your suggestion.
I have a couple of questions:
- When we group statuses in cycles, what eazyBI counts is the time the issue was on those statuses, no matter how many times they come and go from those statuses or whether the issue went to another status not in the cycle and then go to a third status that’s in the cycle, right?
Example (the statuses with “(C)” are part of the cycle)
Backlog (C)=> Analysis <=> Waiting for Third Party (C) => Resolved => Closed
- Can we group statuses based on the same categories (for instance the “waiting” ones, the “working” ones, etc.) regardless their specific use in the corresponding Jira projects? Let me explain:
We use one eazyBI project and import 3 Jira projects.
Here we have different situations regarding the use of statuses
Within the same project
Depending on the Issue Type, the workflows share some statuses and some are different
For instance
** PROJECT INCIDENT MGMT **
Issue type Incident
Waiting statuses
- Backlog
- Needs Approval
- Waiting for Third Party
Issue type Service Request
Waiting statuses
- Backlog
- Needs more info
- Waiting for Third Party
Besides, some statuses are shared among the 3 projects
** PROJECT PROBLEM MGMT **
Waiting statuses
- Backlog
- Waiting for Third Party
** Reopened*
I hope questions are clear enough!
Thanks
W.
HI, @ilze.mezite
I started using your recommendations about Cycles and it seems it will be the solution.
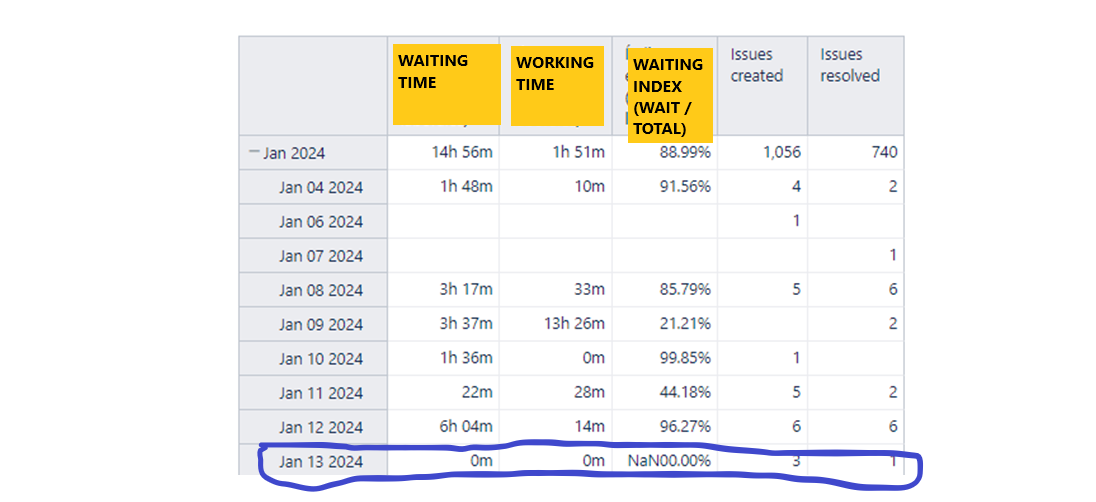
However, when I drill across, I found some strange cases:
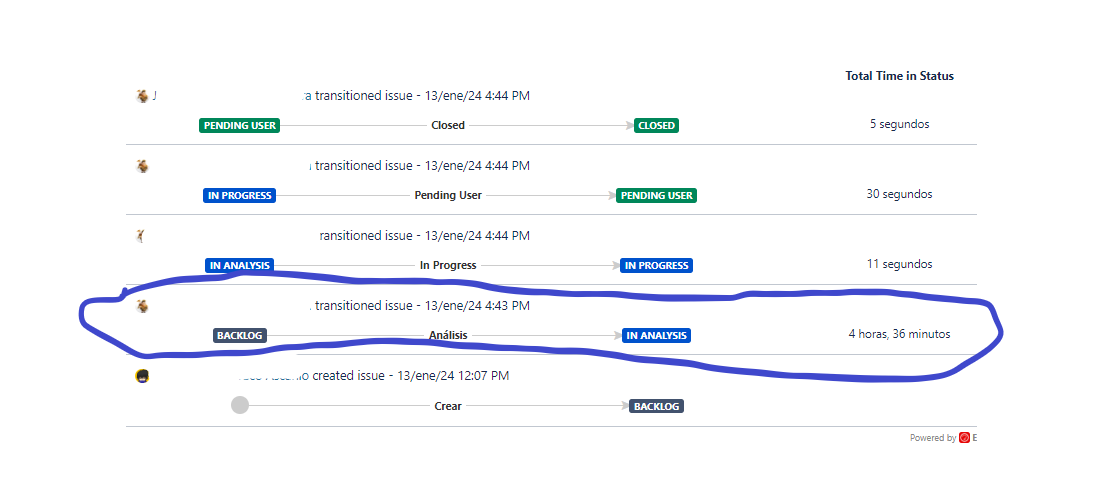
I found a couple of days with the NaN but in this case is easier to find the suspicious case, because it is one of the created.
I checked the issues created on the same day and I found one that started the Waiting time cycle that day, so there is one that matches the criteria to show data on 13th. It also could be I’m missing something.
Any ideas?
Thanks
W.
Hi @ilze.mezite
Did you have the chance to check my previous comment?
Thanks