Hello Good People,
I have a multiselect checkbox field wIth vlaues ABC , DEF , GHI
Im trying to create a measure where it shows total number of ABC only issues and ignores if any of the other two is selected.
Tried using the EXCEPT but its not working as expected.
Hi @gagan_m_s
If checkbox field is imported as a dimension in eazyBI, try creating new calculated measure using this formula:
(
[Measures].[Issues created],
[Checkbox field NAME].[ABC]
)
But the same won’t work with except function. Multi-value fields won’t work with Except in the way you expect.
Instead try using this formula:
(
[Measures].[Issues created],
[Checkbox field NAME].DefaultMember
)
-
(
[Measures].[Issues created],
[Checkbox field NAME].[ABC]
)
It will subtract the ABC issues (where any of values is ABC) from all issues.
Martins / eazyBI
@martins.vanags
See you again and thank you very much for helping me solve the problem many times before.
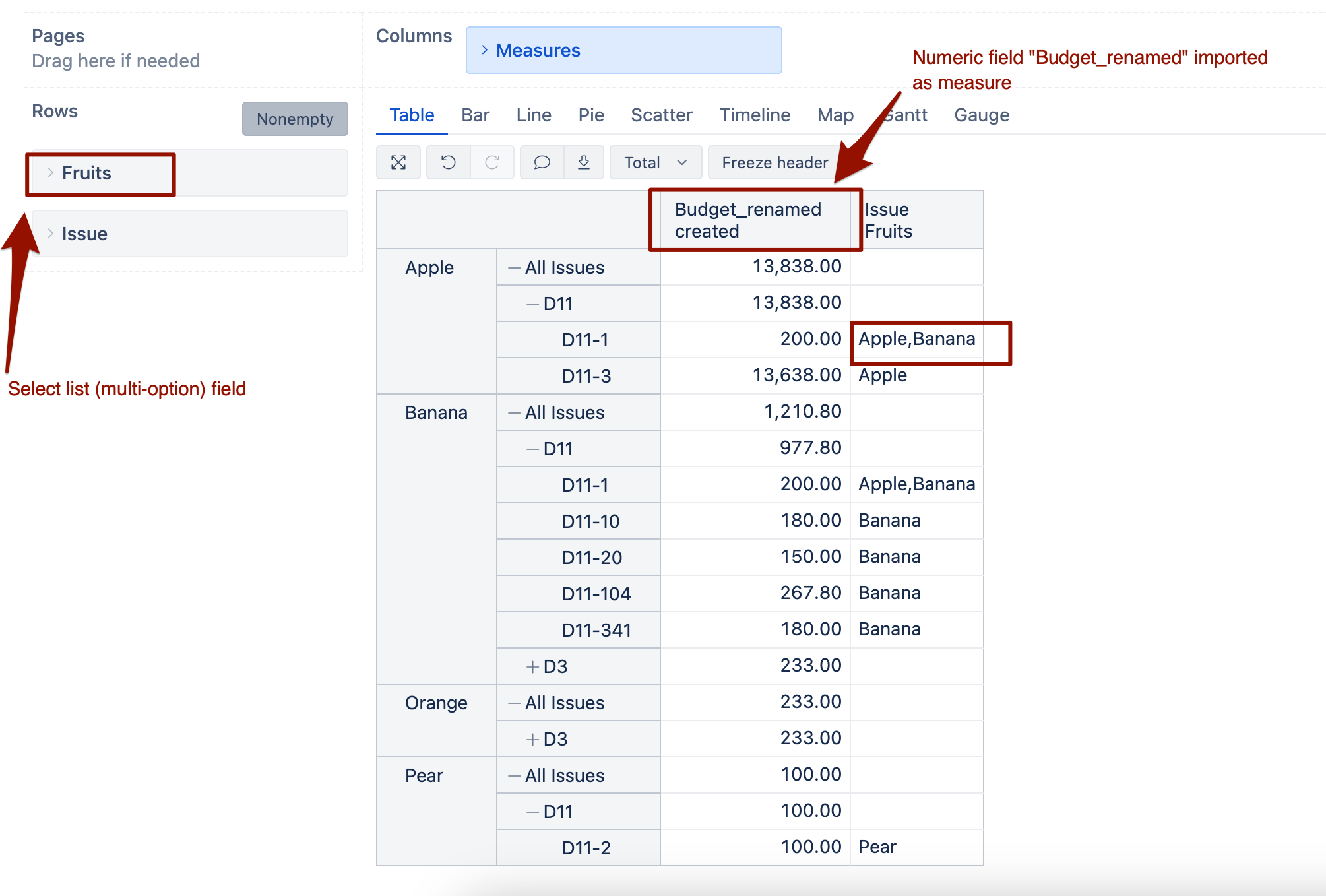
My problem is this: the requirements distribution scenario(需求分发场景) is recorded in Jira Epic, the checkbox type, if more than one value is selected for the requirements distribution scenario, the total man-days(总人天) of the current Epic need to be evenly divided into each requirement distribution scenario, if only 1 is selected, the total man-days belong to that 1 requirement distribution scenario. How does eazyBI calculate the total workload and workload proportion of each requirement distribution scenario among all epic types of all projects in jira? I’m jira server and eazyBI is version 6.6.0.
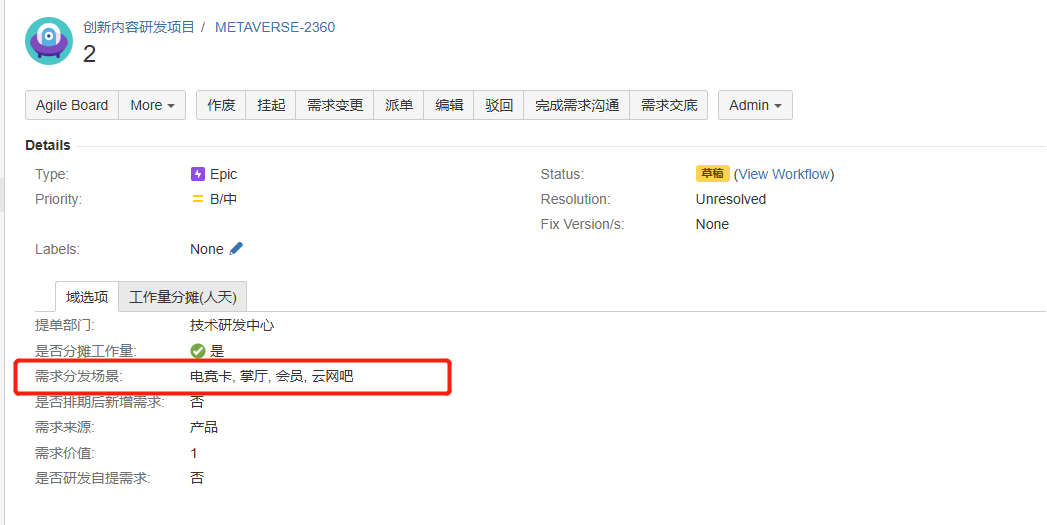
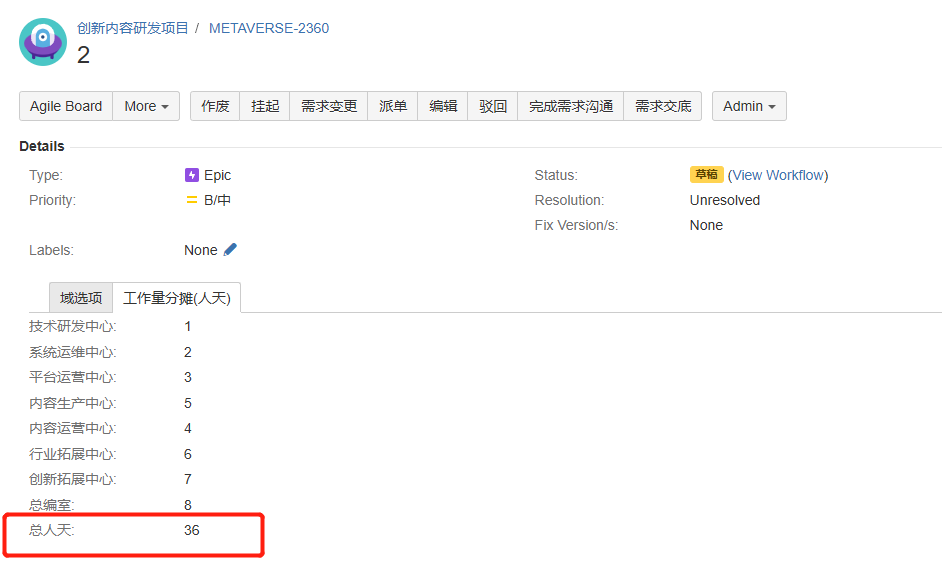
the default behavior when importing Select list (multiple choices) field as dimension would be creating a multi-value dimension that would duplicate results for issues with many options selected in particular field.
Given your example, it would mean if user selects all 3 options from the “requirements distribution scenario” dimension page filter, the report would duplicate “total man-days” three times for the epic and would give you result 108 for the epic in total man-days
If the “requirements distribution scenario” dimension is in rows, the result 36 would be displayed against each of 3 options for the epic.
There could be an option to create a calculated measure that divides that automatic result by the number of options selected in the field for each issue, but usually, these are queries that iterate through all issues and make the report slower.
The code for the calculated measure would depend on the layout (definition) of the report. If you need help with formula, please share the report definition with us.
By the way, I strongly recommend upgrading the eazyBI version to have all the recent features available.
Martins / eazyBI
@martins.vanags I am using Jira Server, and my eazyBI license is permanent but cannot be upgraded anymore. How can I achieve my requirement by creating a calculated measure?
Try this code to count results by “created date”
CASE WHEN
[Measures].[total man-days created]>0
THEN
[Measures].[total man-days created]
/
SUM(
Filter(
DescendantsSet(
[Issue].CurrentMember,
[Issue].[Issue]
),
Not isEmpty([Measures].[Issue total man-days])
),
[Measures].[Issues created]
)
END
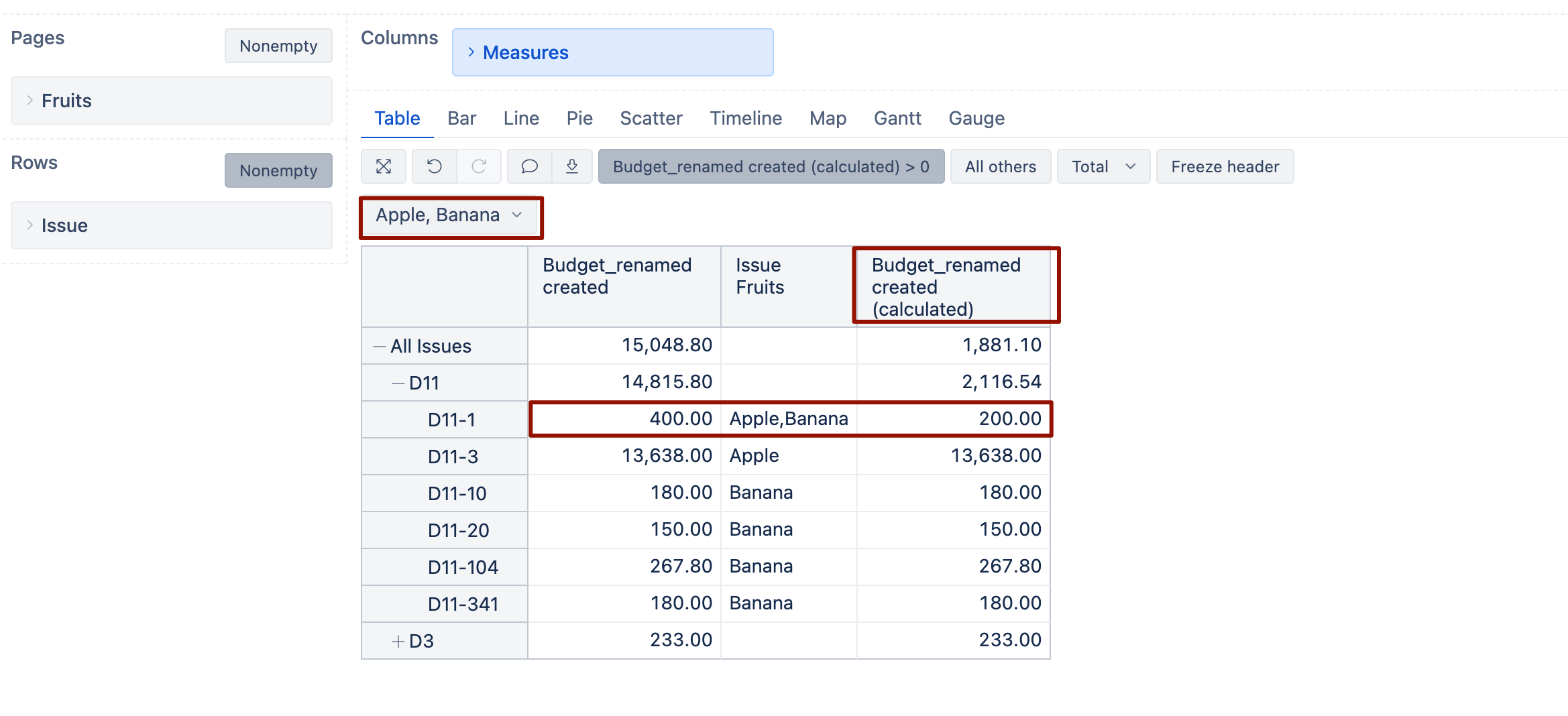
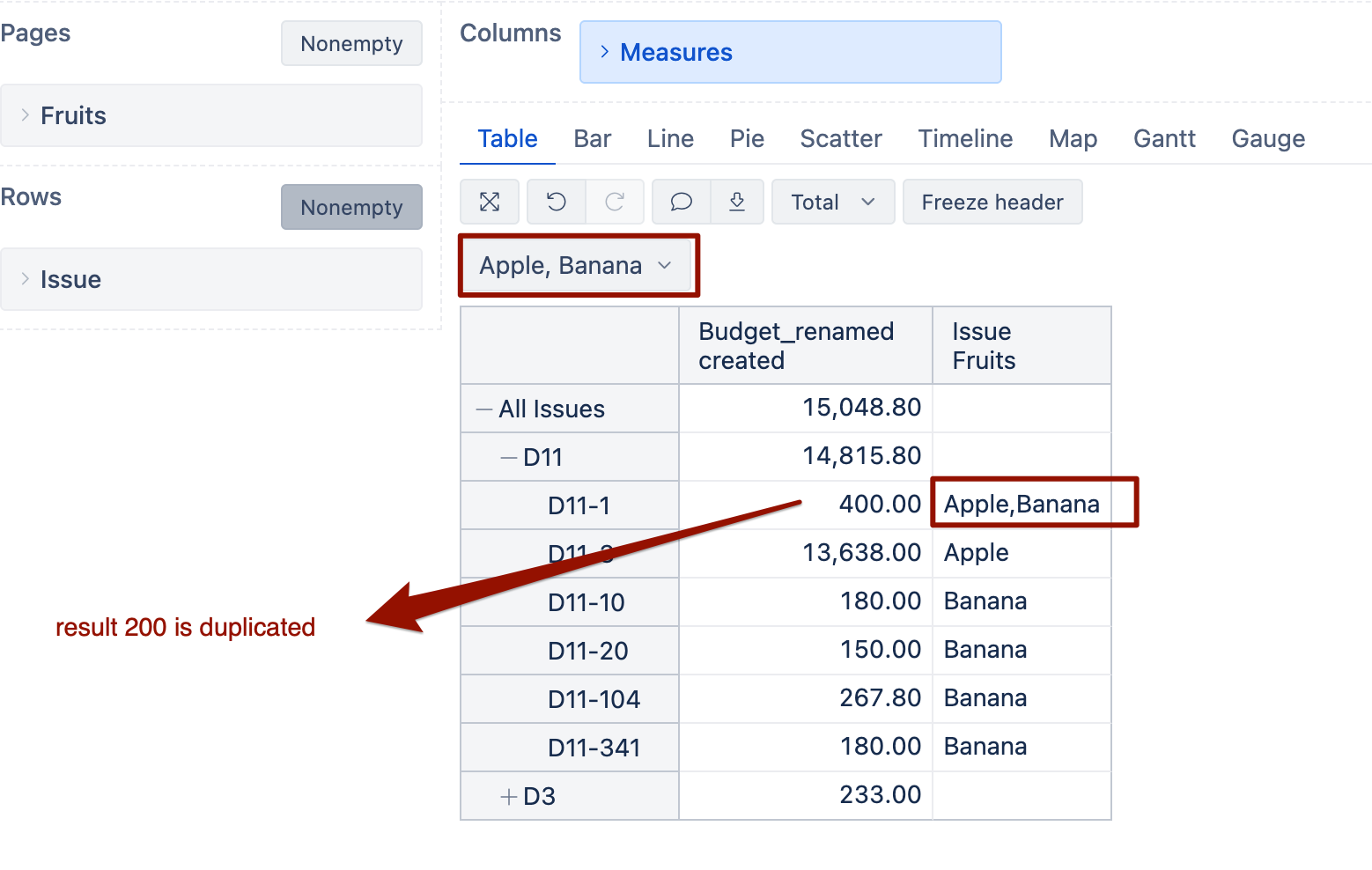
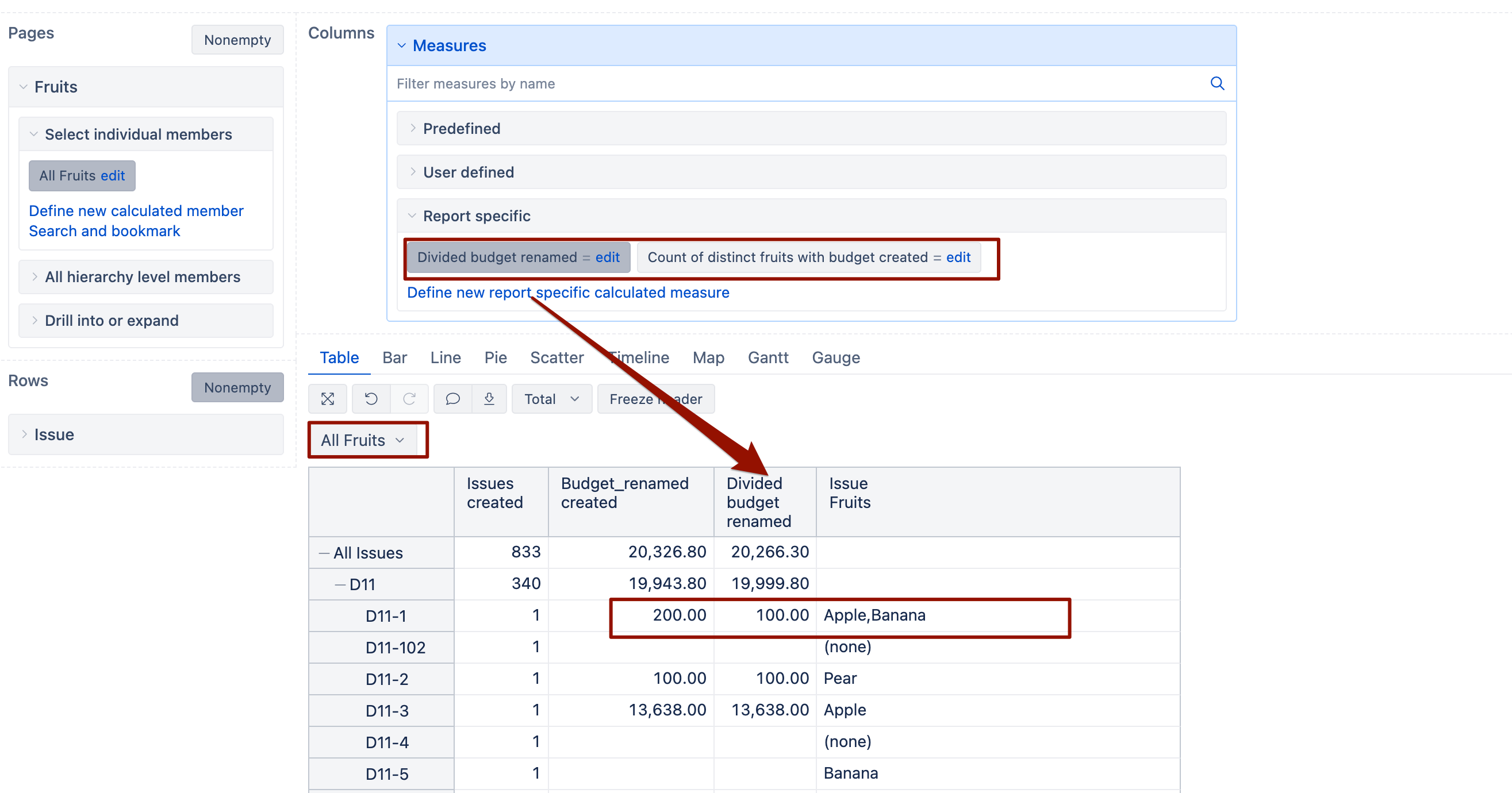
@martins.vanags Hi,you seem to have misunderstood my meaning. My requirement is as follows:
If I have two Jira epic issues, in the first epic issue, the “requirements distribution scenario” has selected four values A, B, C, and D, and the “total man-days” value is 36. This needs to be evenly divided into four parts, so the “total man-days” for A, B, C, and D are all 9. In the second epic issue, the “requirements distribution scenario” has selected two values A and B, and the “total man-days” value is 7.7. This needs to be evenly divided into two parts, so the “total man-days” for A and B are both 3.85. In the end, my dimension of interest is with “requirements distribution scenario” as rows and “total man-days” as columns. The “total man-days” for A would be 9 + 3.85 = 12.85, for B would also be 9 + 3.85 = 12.85, for C would be 9, and for D would be 9.
in that case, try this formula for distributed calculation
CASE WHEN
[Measures].[total man-days created]>0
THEN
SUM(
Filter(
DescendantsSet(
[Issue].CurrentMember,
[Issue].[Issue]
),
Not isEmpty([Measures].[Issue total man-days])
),
CASE
WHEN
[Measures].[Count of distinct requirements distribution scenario with total man-days created]>0
THEN
(
[Measures].[total man-days created]
/
[Measures].[Issues created]
)
/
[Measures].[Count of distinct requirements distribution scenario with total man-days created]
END
)
END
Note it is referencing another calculated measure “Count of distinct requirements distribution scenario with total man-days created” that is defined with this formula:
Cache(
SUM(
DescendantsSet(
[requirements distribution scenario].CurrentMember,
[requirements distribution scenario].[requirements distribution scenario]
),
CASE
WHEN [Measures].[total man-days created] > 0
THEN 1
END
)
)
Martins / eazyBI
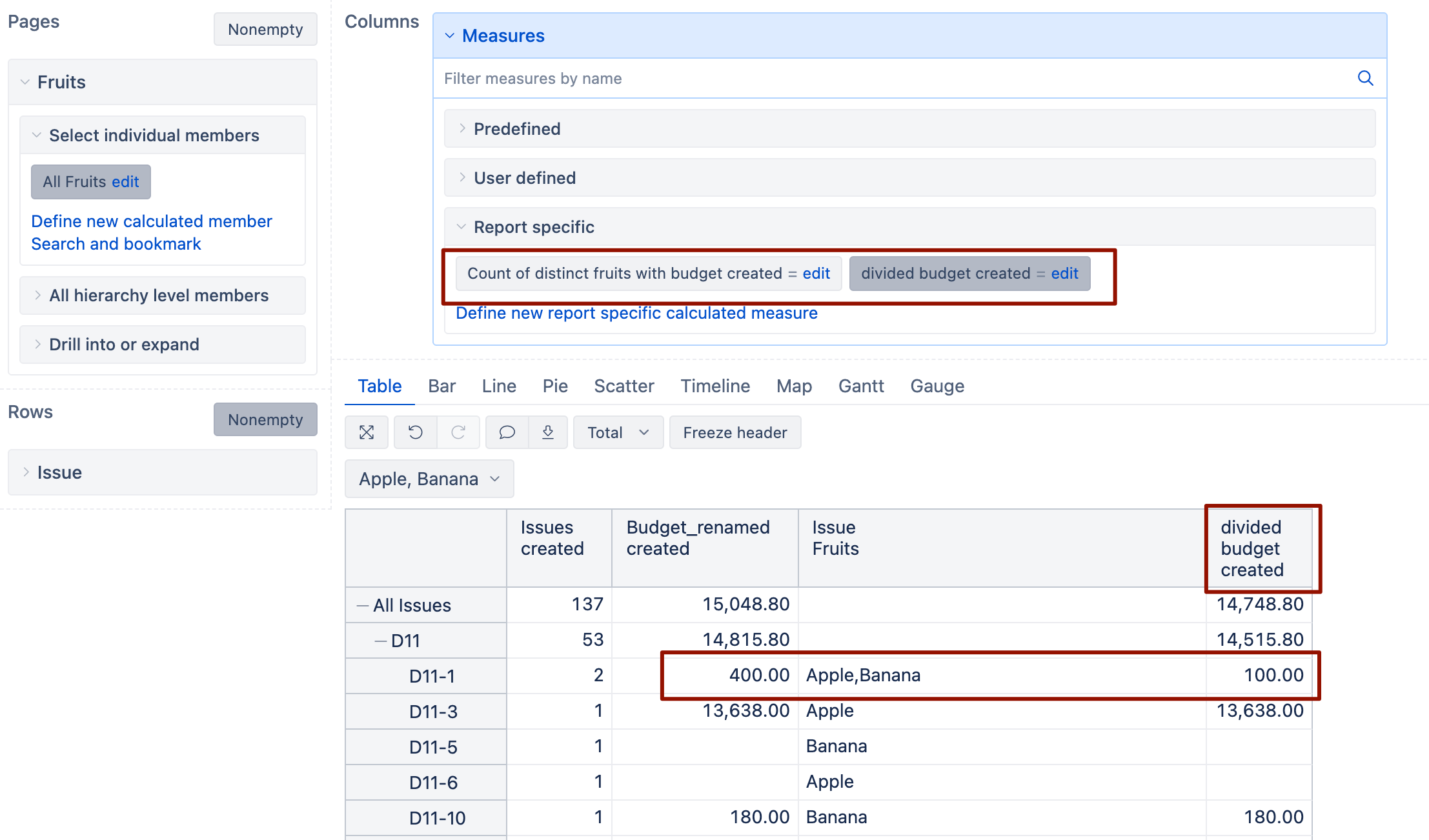
@martins.vanags Can I use “requirements distribution scenario” as rows to summarize the workload for each “requirements distribution scenario”? ![]()
Yes, I believe so.
The formula should work correctly also for the dimension in rows.
Martins / eazyBI
But the result I got is incorrect. Please see my screenshot.
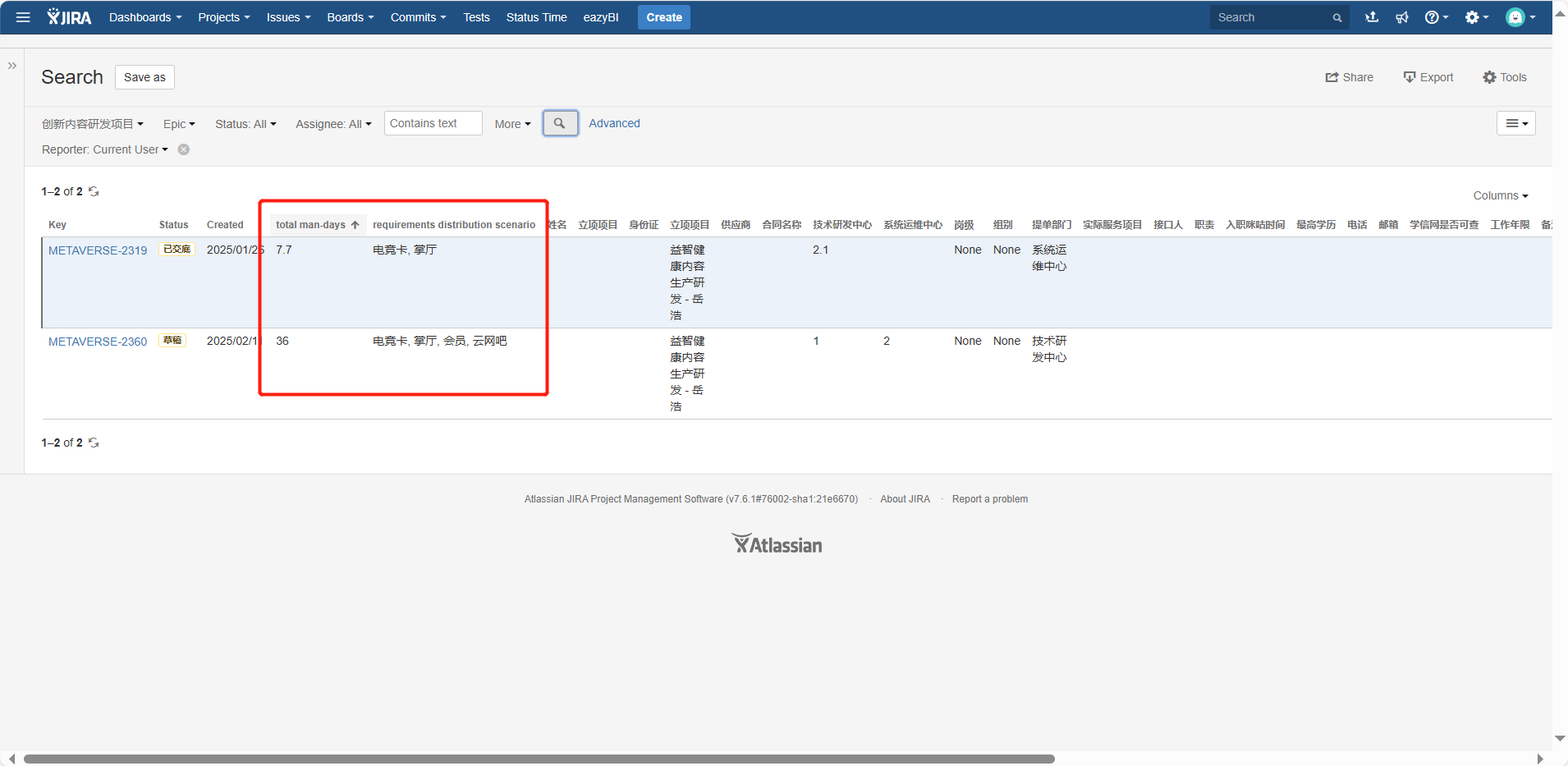
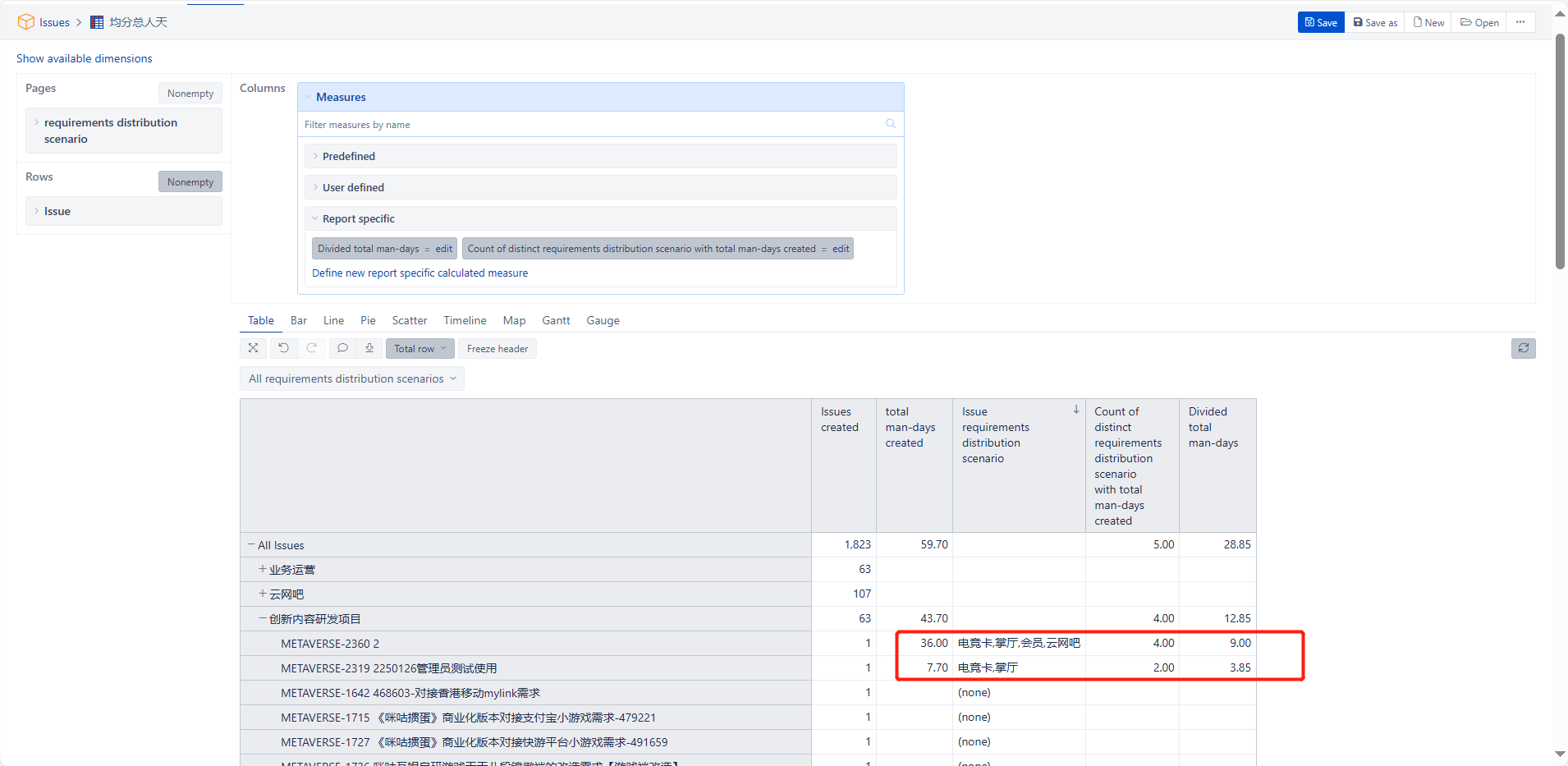
The data displayed according to the rows and columns in your screenshot is correct. However, I want to display it in the format shown below, but the data doesn’t match. How can I adjust it?
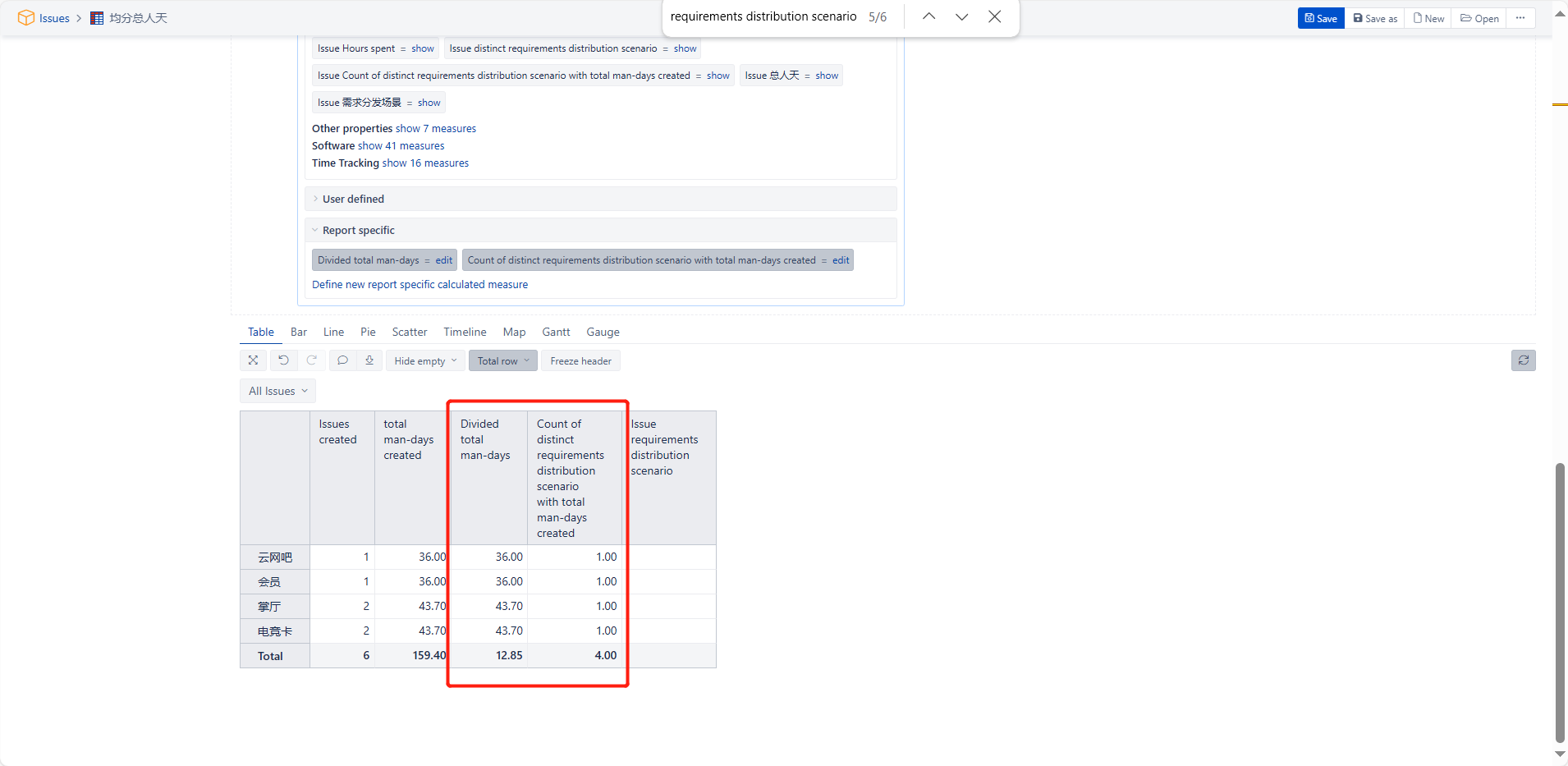
It looks like the previou formula didn’t work as I expectd for “requirements distribution scenaro” dimension.
Try this update for calculated measue “Count of distinct requirements distribution scenario with total man-days created”
Cache(
CASE
WHEN [Issue].CurrentHierarchyMember.level.name = "Issue"
THEN
Count(
[requirements distribution scenario].[requirements distribution scenario].GetMembersByKeys(
[Issue].CurrentMember.get('requirements distribution scenario')
)
)
END
)
It should fix the problem.
Now it would count requirrement distribution scenario for all issues correctly and it should be enough to make the final calculation.
Martins / eazyBI
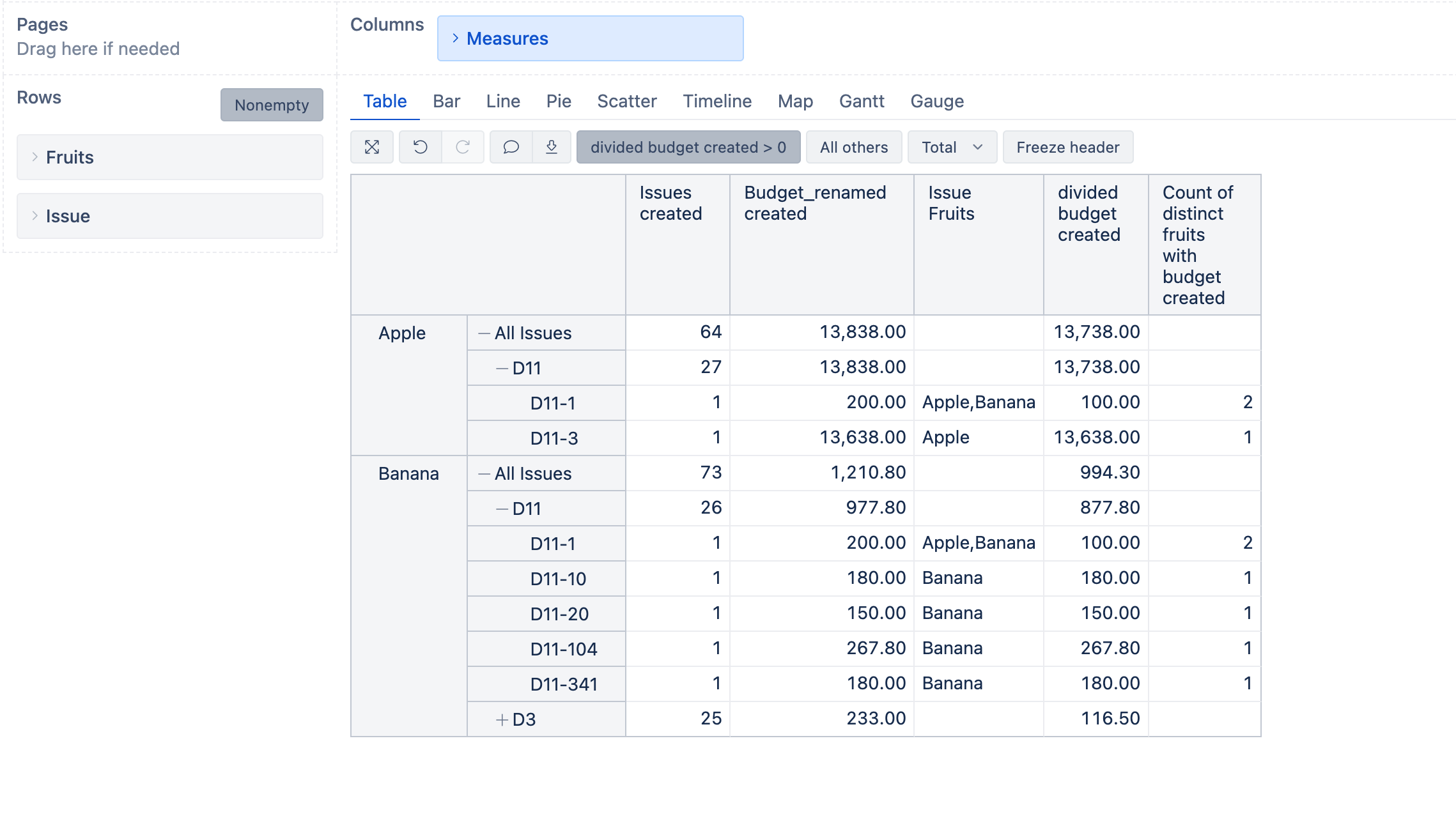
@martins.vanags
Yes, that’s correct this time,thank you very much for your help.
Also, I have another question: how would I write the script to calculate the percentage of ‘Divided total man-days’ relative to the total ‘total man-days created’ across all scenarios?"
Perhaps you don’t need new scripts for the percentage calculation.
Check this page: Add standard calculations
Maybe you can use " % of total calculation for the already existing column.
Martins / eazyBI
@martins.vanags “Thank you very much for your assistance, but I’m finding eazyBI quite challenging to use, and MDX scripting is particularly difficult.” ![]()
1 Like
@jingjing
Thank you for this honest feedback.
That is why we have an experienced support team at eazyBI available.
If you can’t find the right answer to your question, you can always contact support@eazybi.com directly.
Martins / eazyBI