Hi all, we need to create a new measure with a sprint substring . For example if we had 3 sprints:
Sprint 10: s p commited 10, s p completed 5,
Sprint 100: s p commited 6, s p completed 3,
Sprint 20: s p commited 5, s p completed 5
We need a new measure to group the sprint have number 1 with correspondig sp commited and sp completed and the same whith number 2.
Sprint reports uses specific sprint scope measures that work on historical data (Sprint issues committed, Sprint issues completed, etc.).
Those measures will not work with new dimension calculated with JavaScript during import. This new dimension will not have any reference to historical measures required for sprint reports.
You would like to define calculated members in Sprint dimension using some regex filter. Here is an example of Sprint calculated member ending with 1:
You can use any other RegEx expression to support your case.
Some measures might not work with calculated Sprint members, default committed measures, in particular. You would like to use a bit modified version of it, for example, this one:
( [Measures].[Transitions to],
[Transition Field].[Sprint status],
[Sprint Status].[Active],
-- An issue was in a sprint at a sprint start time
[Issue Sprint Status Change].[Future => Active],
[Time].CurrentHierarchy.DefaultMember
)
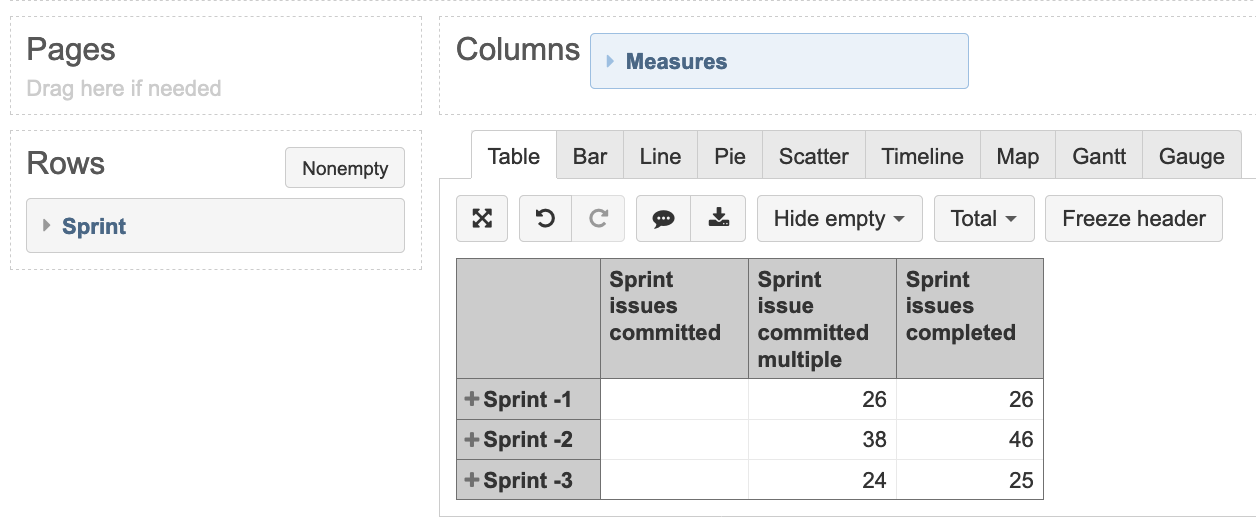
Here is an example report for multiple sprints in our demo account. The report example is designed for Active Sprints burndown. But the ideas used there might be applicable for other cases as well.
Thank you for your response Diana, we understand the solution and troubles of working with sprints and issues together. But your proposal does not fit our needs, because we need to create new columns to group using substrings of the sprint names . If we use a filter with ‘match’ clause, the result in column is the name of de sprint, not the filter applied.
eazyBI does not support using one dimension in Rows and in Columns.
You can create another dimension Sprint key using JavaScript calculated custom fields. It could be quite tricky with Sprint custom field. It has a complex data structure and contain multiple values. You can check issue JSON to see how Jira stores values for Sprint custom field. This data structure will be available via JavaScript as well.
You can access issue JSON by modifying an issue URL. Please modify the URL of the issue replacing browse with rest/api/latest/issue. Check how the value for Sprint custom field (search by custom field ID) is stored.
However, in this case, the historical measures (typically used for Sprints) will not work with dimension created with JavaScript calculated custom fields and you can have a limited used for this new dimension.
The approach with calculated custom fields in Sprint dimension might be the closest solution you might consider. This allows you to use match by substring of sprint name. You can check more regular expression examples for machines sprints by substring.
You can use an option expand (click on plus sign in the report where calculated members are used) to expand calculated members and see sprints pulled in there. The report with expanded Sprint calculated members would look similar to yours.