Hi,
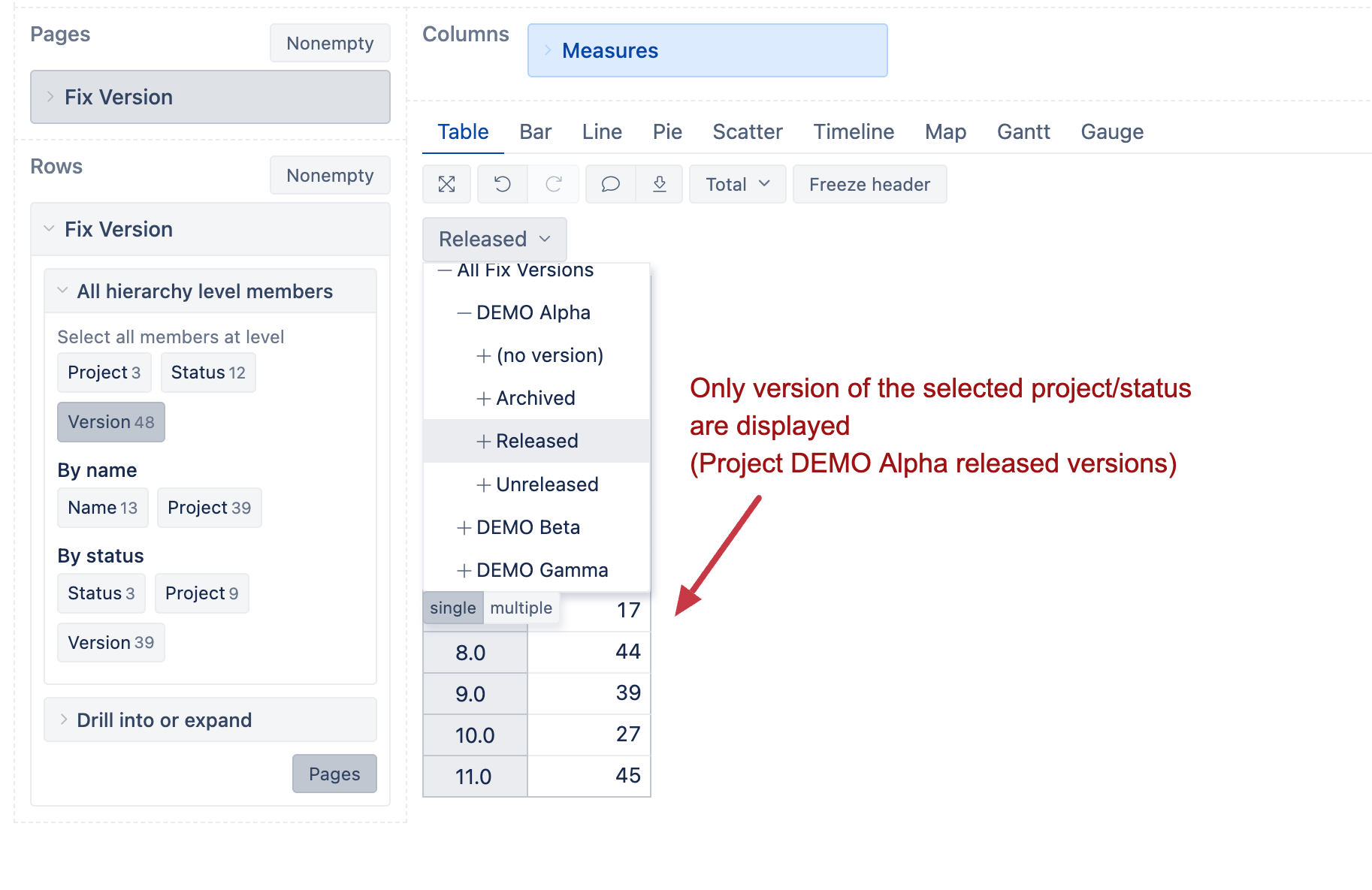
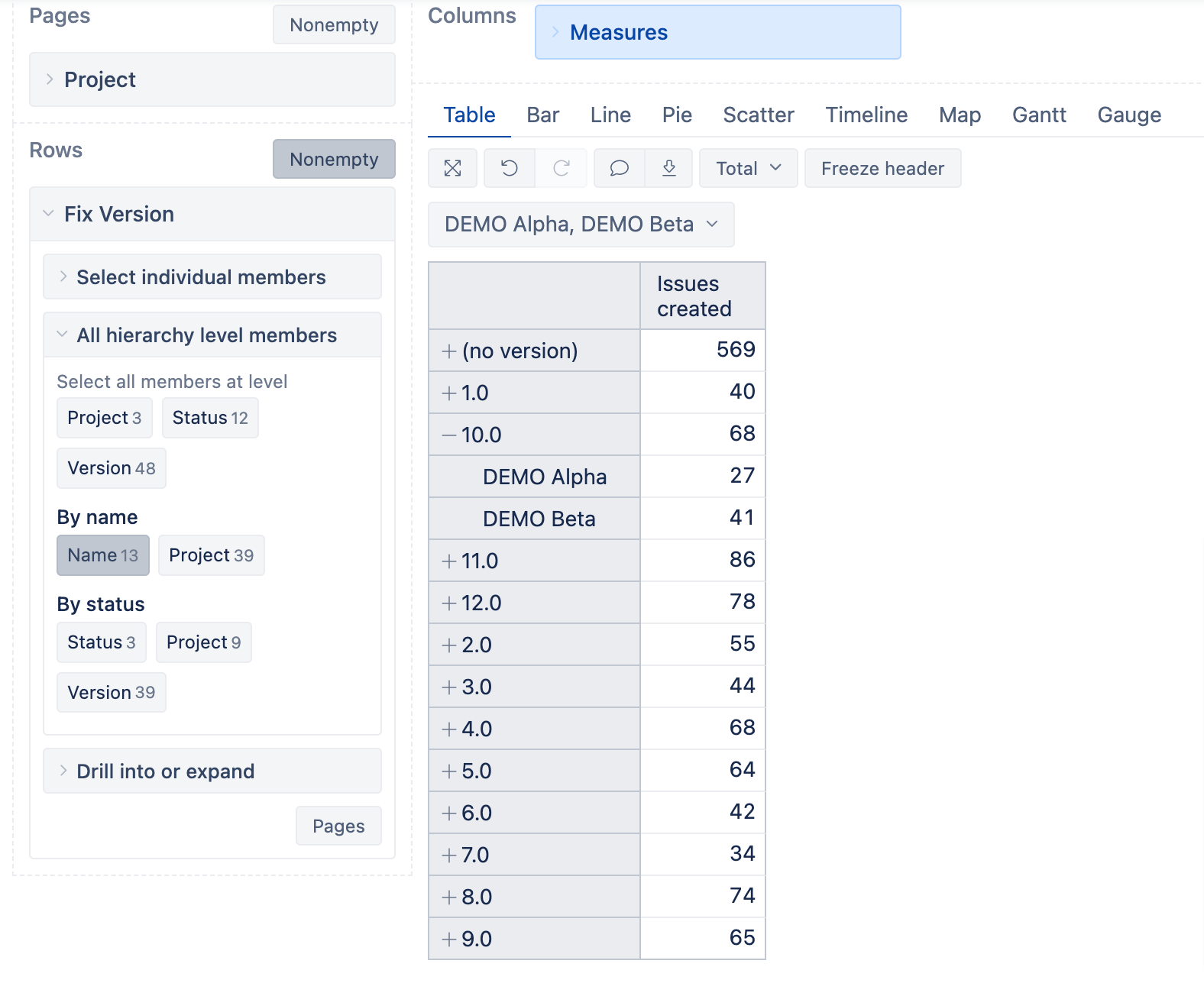
In our use case of using Jira Software, we are using a very large amount of versions for each Jira-project. We have multiple Jira-projects used in parallel, and each of them, generally, has similar versions.
For example, projects A & B both have versions a,b,c,d,e, etc.
When importing the projects to eazyBI we have issues with our method.
-
There are too many versions imported, so eazyBI is having a hard time handling them. And the versions are identical in their names, because version a is located both in projects A & B
-
Practically, in each filter of the data, I don’t need all the versions, but rather only the used versions, but even though eazyBI knows to give only the used ones, due to the numerous number of versions, I can’t use aggregation even to group together a specific group of versions.
Do you have any idea how to resolve this?