Hello eazyBI community,
I’m trying to import a CSV file to enrich existing JIRA issue data, but I’m having trouble with the correct configuration.
Context:
-JIRA issues have a custom field called “Coda Project ID”
- I have a CSV file with two columns:
Coda Project ID (values like: P2475, P2477, etc.)
Coda Project Name (corresponding project names)
The Goal is to display project names instead of IDs in reports
What I’ve tried:
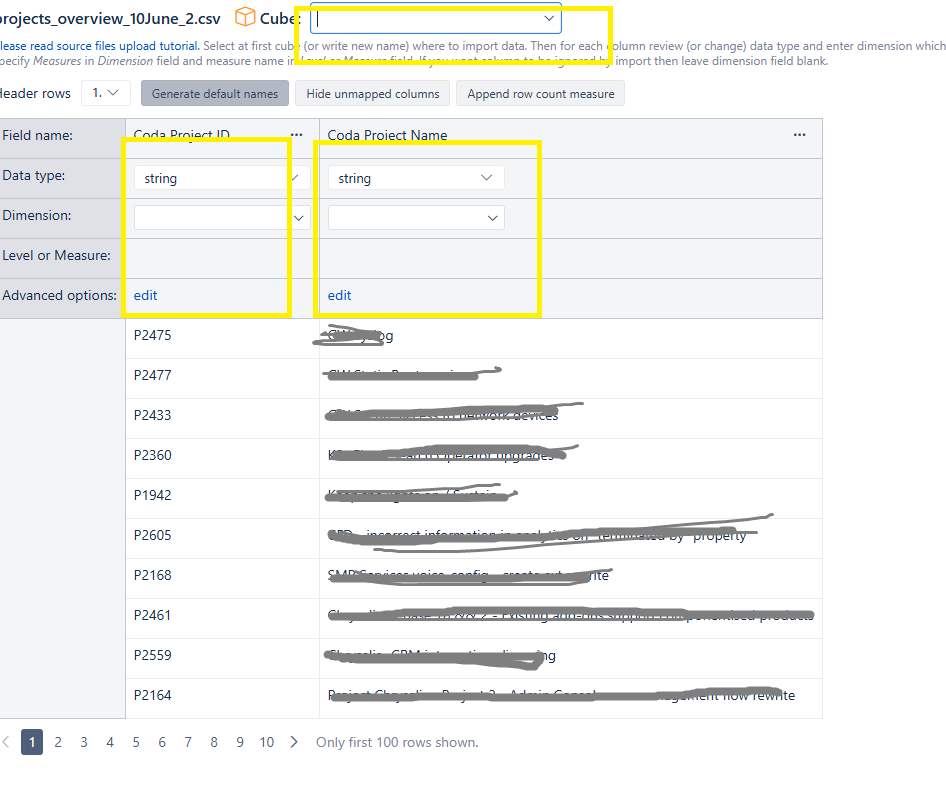
-Uploaded CSV to Source Files in Issues cube
-Various dimension configurations but getting validation errors
-Different mapping approaches suggested by ChatGPT
-Result: Shows “10 rows imported” but data isn’t linked to Issues
Questions:
- What should I enter for each column’s:
Dimension field?
Level or Measure field?
Advanced options?
- How do I ensure the CSV “Coda Project ID” column maps to the JIRA field “Coda Project ID”?
- Should I use “Skip missing” option for issues without Coda Project IDs?
I’ve attached a screenshot showing the configuration screen. Any guidance on the correct setup would be greatly appreciated.
Environment: JIRA Data Center with eazyBI
Thank you!
Stefania
I’ve verified:
-CSV header is exactly ‘Coda Project ID,Coda Project Name’
-JIRA field name is exactly ‘Coda Project ID’
-The CSV contains matching values (e.g., P1819)
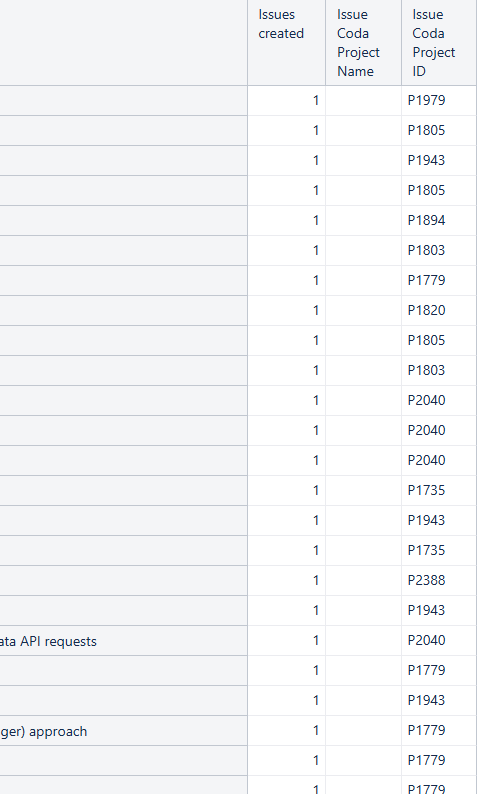
It seems that import completes without errors
But Issue Coda Project Name shows ‘(none)’ for all issues, I cannot understand why
It seems that Import completes successfully but data doesn’t link to Issues
Details:
- JIRA field: “Coda Project ID” (confirmed exact name)
- CSV header: “Coda Project ID” (exact match)
- Import settings: Both columns set to Issue dimension
- Import result: Success, no errors
- Problem: Issue Coda Project Name property is not created
- The Coda Project ID values exist in both JIRA (P1979, etc.) and CSV
Question: How can I force eazyBI to map the CSV column to the existing JIRA custom field?
Hi @scardos,
You reached out to us in an internal conversation as well. I’ll share the suggestions from that conversation with the community.
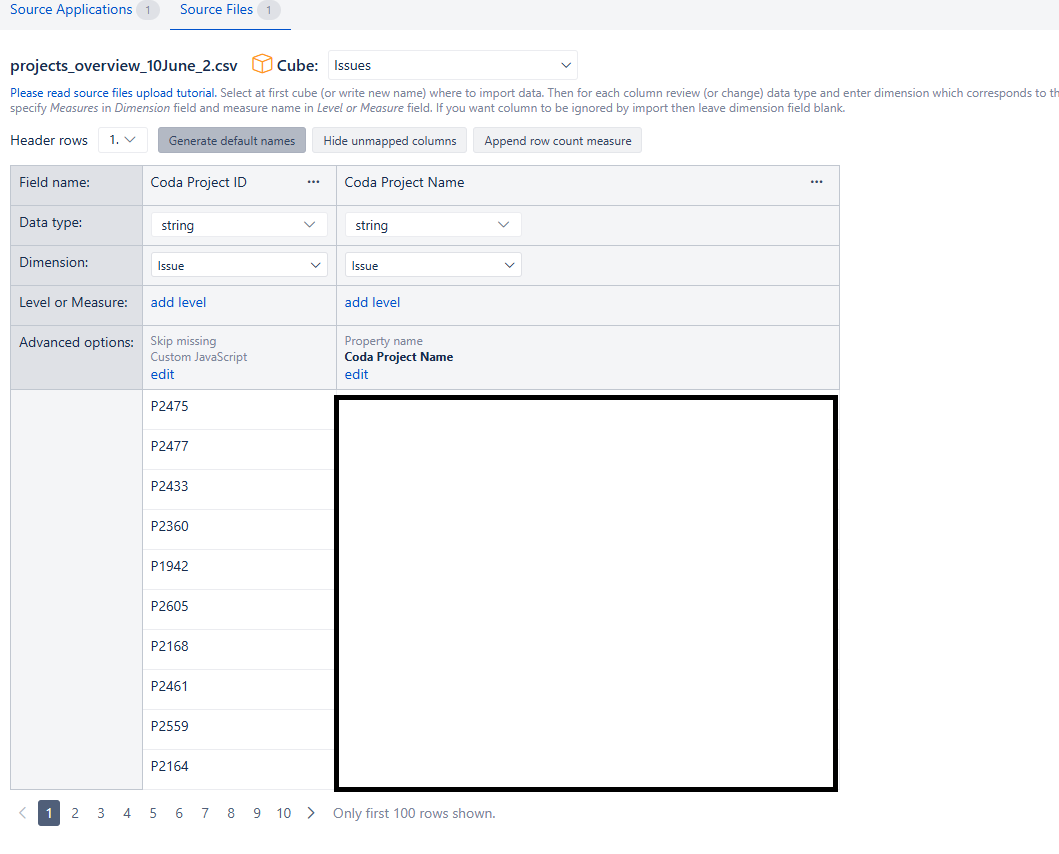
You can import additional data (measures and properties) into the Jira issues cube and tie it to single-value custom fields. Please see more details regarding that here - Advanced settings for custom fields.
After enabling the setting mentioned in the documentation page above, import data without the field, and then again with the field selected for import. Then you can proceed to the CSV file data mapping, select the “Issues” cube, and choose the custom field in the dimension selection for both columns. In the “Coda Project ID” column, specify the additional option “Skip missing” for the eazyBI import to ignore members in the CSV file that don’t appear in the custom field dimension members. Otherwise, the import will fail when non-existent members are encountered. In the “Coda Project Name” column, specify the import as a property.
Finally, to view the project names instead of IDs, I recommend creating a new hierarchy based on this additionally imported property - Custom hierarchies.
Let me know if you have any questions or suggestions.
Best,
Hi, thank you very much for your support. I managed to do the trick
1 Like