Hi folks,
We have certain teams (eg. Backend) that complete tickets within their own Jira Projects during a Sprint, but also complete tickets for other teams’ Jira Projects based on whether a certain component (eg. ‘Backend’) is added to a ticket. All teams have the same sprint start and end dates, regardless of what Jira Project their tickets are stored. I am looking to put together a report that displays the cumulative story points completed for completed sprints. I created the measure below to return the number of story points that are ‘Done’ at the close of a sprint for tickets that are in the Jira project Backend, and tickets that have a component backend.
Sum(Filter(
Descendants([Project].CurrentMember, [Project].[Project]),
[Project].CurrentHierarchyMember.Name = 'Backend'),
(([Measures].[Sprint Story Points at closing],
[Transition Status.Category].[Done]))) +
Sum(Filter(
Descendants([Project].[Component].CurrentMember, [Project].[Component]),
[Project].[Component].CurrentHierarchyMember.Name MATCHES '^Back.*'),
([Measures].[Sprint Story Points at closing],
[Transition Status.Category].[Done]))
After using Pages to identify the close date of each sprint I end up with:
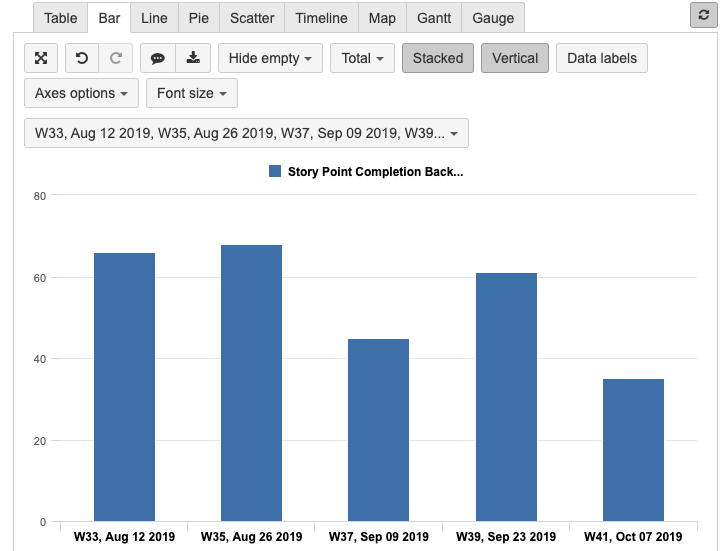
This gives me all the story points I need, but as I understand it I need to use the Time dimension rather than the Sprint dimension in Rows. This is due to the fact that tickets resulting from this measure span multiple Sprints and Projects. So, I can’t clearly convey the sprint that each bar represents to other teams less familiar with sprint start and end dates.
If I could somehow replace the ‘W33, Aug 12 2019’ label with ‘Q3 Sprint 4’ that would clearly convey the sprint that the Backend team completed work in. Alternatively, if having the sprint (or sprints) on the x-axis isn’t possible, I may be fine with having a stacked bar chart displaying the different Jira Projects’ Sprints (eg. iOS, Android, Web) that the Backend team completed work in. Can someone weigh in on this?
Separate but related, I believe my filter could be improved to better match the below JQL query.
project = Backend OR component = Backend
In my current measure, if a ticket were in the project ‘Backend’ and for some reason had the component ‘Backend’ the ticket’s story points would be double counted. What I should be using is MDX’s version of an ‘OR’ statement somehow. Any feedback on that would be welcomed!