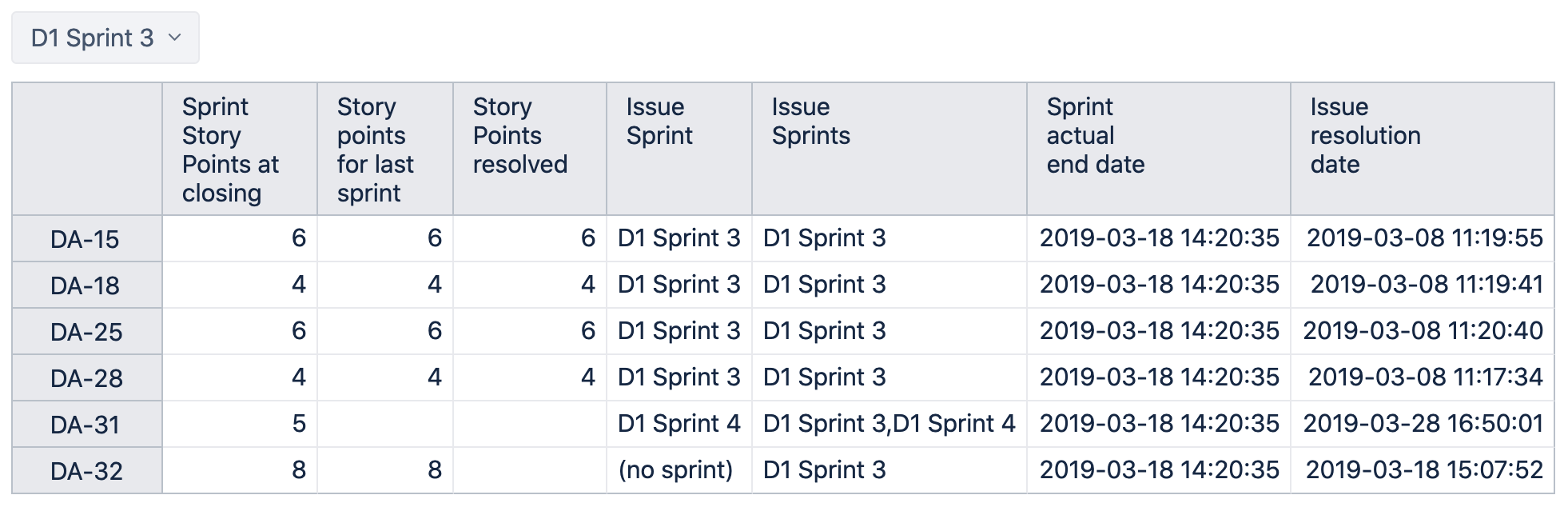
In our JIRA system we have issues assigned to several sprints. Evaluation of those isues in general is difficult since those issues ar accounted to several sprints. In my case I want those issues to be accounted to the last sprint they are in. This is the approach I took.
Let’s assume that the sprints that are relevant for evaluation are MySprint1, MySprint2, …
then first I define a calculated member [Sprint].[MySprints] in the Sprint dimension as follows and as already seen here in the community
Aggregate (
Order (
Filter (
[Sprint].[Sprint].Members,
[Sprint].CurrentMember.Name MATCHES '^MySprint.*' AND
NOT isEmpty([Sprint].CurrentMember.Get('Start date'))
),
[Sprint].CurrentMember.Get('Start date'), BASC
)
)
Then the idea is to count the number of occurences of an issue in all sprints and compare that versus the number of accumulated occurences at a specific sprint. If those numbers are the same I know we are at the last sprint the issue is in.
So we define a measure [Total InSprint Count] as follows
Aggregate (
ChildrenSet (
[Sprint].[MySprints]
),
[Measures].[Sprint issues at closing]
)
and a second measure [Current InSprint Count] as follows
CASE WHEN
-- This is just to get the totals right
[Sprint].CurrentMember IS [Sprint].[MySprints]
THEN
Aggregate(
Cache (ChildrenSet([Sprint].[MySprints])),
[Measures].[Sprint issues at closing]
)
ELSE
-- for a sprint in the set of MySprints
-- it adds up the occurences in all sprints up to the one specified
Aggregate (
Head (
Cache (ChildrenSet([Sprint].[MySprints])),
Rank ([Sprint].CurrentMember,
Cache (ChildrenSet([Sprint].[MySprints]))
)
),
[Measures].[Sprint issues at closing]
)
END
Based on this we then define a measure [My Unique Measure]
NonZero (
SUM (
Filter (
Descendants ([Issue].CurrentHierarchyMember,[Issue].[Issue]),
[Measures].[Sprint issues at closing] > 0
AND
([Issue].CurrentMember, [Measures].[Current InSprint Count]) =
([Issue].CurrentMember, [Measures].[Total InSprint Count])
),
(
[Measures].[some story point measure],
[Sprint].DefaultMember
)
)
)
If you have further sugggestions on improving or simplifying this approach, please let me know