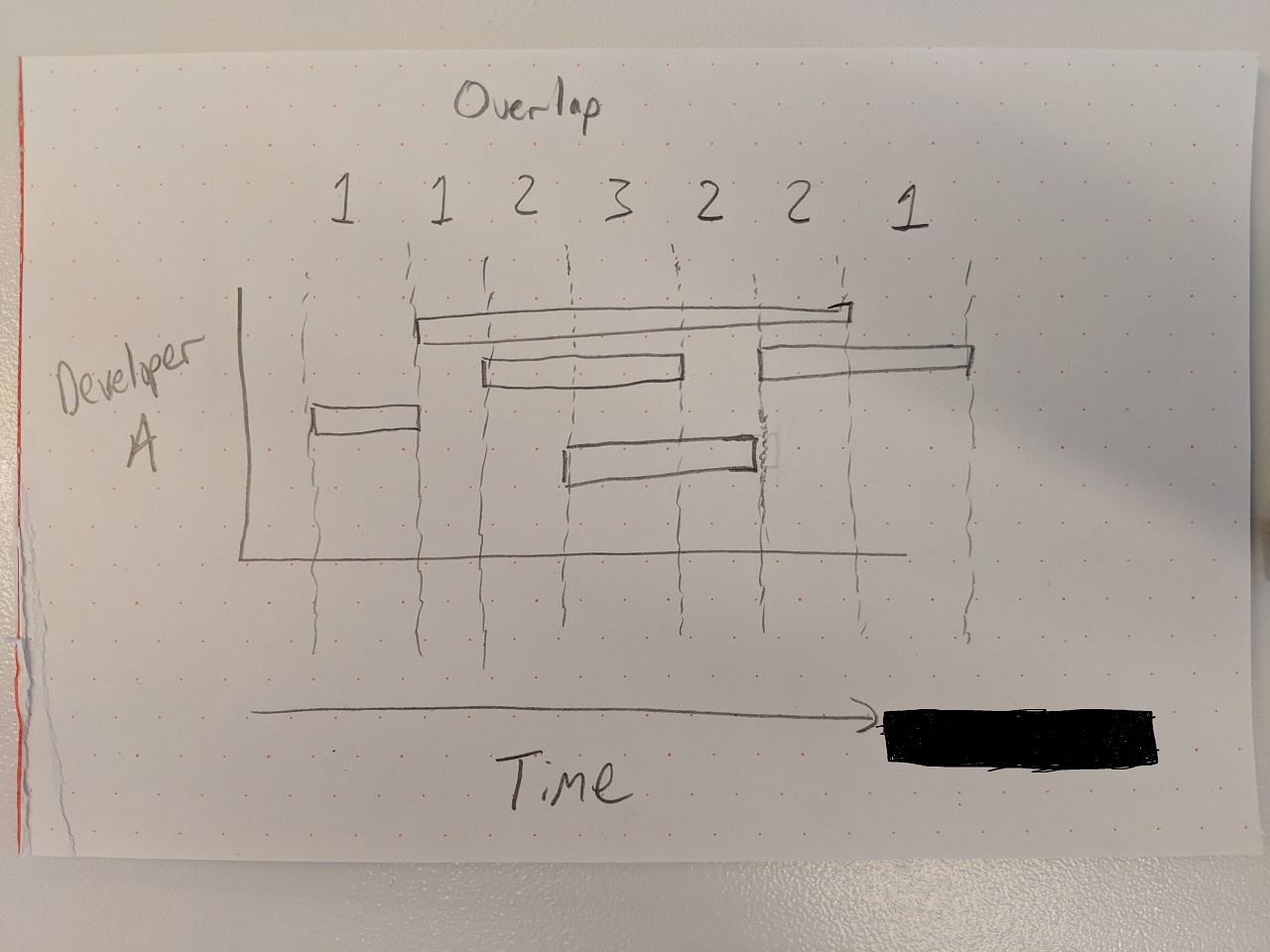
I’ve been trying to figure out a way to aggregate the impact multiple issues in progress have on the overall cycle time.
Ex:
Team EazyBI has 5 developers. When each developer takes on one issue at a time and finishes it before picking up the next item, their average cycle time is 4 days. When a developer takes on two issues at a time and finishes them, their average cycle time increases to 9 days (an increase of 1 day overall than if they had done both items in serial rather than parallel). When they take on three issues at a time and finish them, their average cycle time increases to 19 days (an increase of 7 days overall compared to if they had done all three in serial rather than parallel).
The report would need to calculate when there are two or more items in progress (transition status dimension), per assignee, and only aggregate when those items are actually being worked on simultaneously.
I would also like to separate the aggregated time to show what happens when there’s 1 item in progress per assignee, 2 items in progress at the same time per assignee, 3 items in progress at the same time per assignee, etc.
Basically, I haven’t been able to figure out a way to get concurrency.
From a different report I have a base calculation to gather Min and Max time for a set of issues, as well as their standard deviation. That calculated measure for the Minimum is:
Cache(
Min(
Filter(
Descendants([Issue].CurrentMember, [Issue].[Issue]),
([Measures].[Issues resolved], [Transition Status].CurrentHierarchy.DefaultMember) > 0
AND [Measures].[Days in transition status] > 0
-- Including Issue resolution, Issue status, and Issue type in the calculated member speeds up the report significantly compared to putting those dimensions in pages and filtering a larger dataset
AND ([Measures].[Issue resolution] = "(unresolved)" OR
[Measures].[Issue resolution] = "Completed")
AND [Measures].[Issue status] = "Done"
AND ([Measures].[Issue type] = "Story" OR
[Measures].[Issue type] = "Spike" OR
[Measures].[Issue type] = "Bug" OR
[Measures].[Issue type] = "Task")
),
[Measures].[Days in transition status]
)
)
I’m thinking that I would put assignee dimension into Rows after the Story Point dimension. That way in the calculated measure I could have something like:
AND [Measures].[Concurrency] = 2
in that function so that it would only return the Minimum amount of time it took when 2 items were in progress for that assignee.
I could then change the Concurrency value to 3, or 4, or however many to see the difference in time it takes.
I hope this makes sense.
Again, I’m basically trying to measure the impact that taking on multiple items at a time has on actual cycle time. In other words, why it’s so important to have WIP Limits.
This new report would be a sibling of a prior report created at (Potentially) Complicated Chart
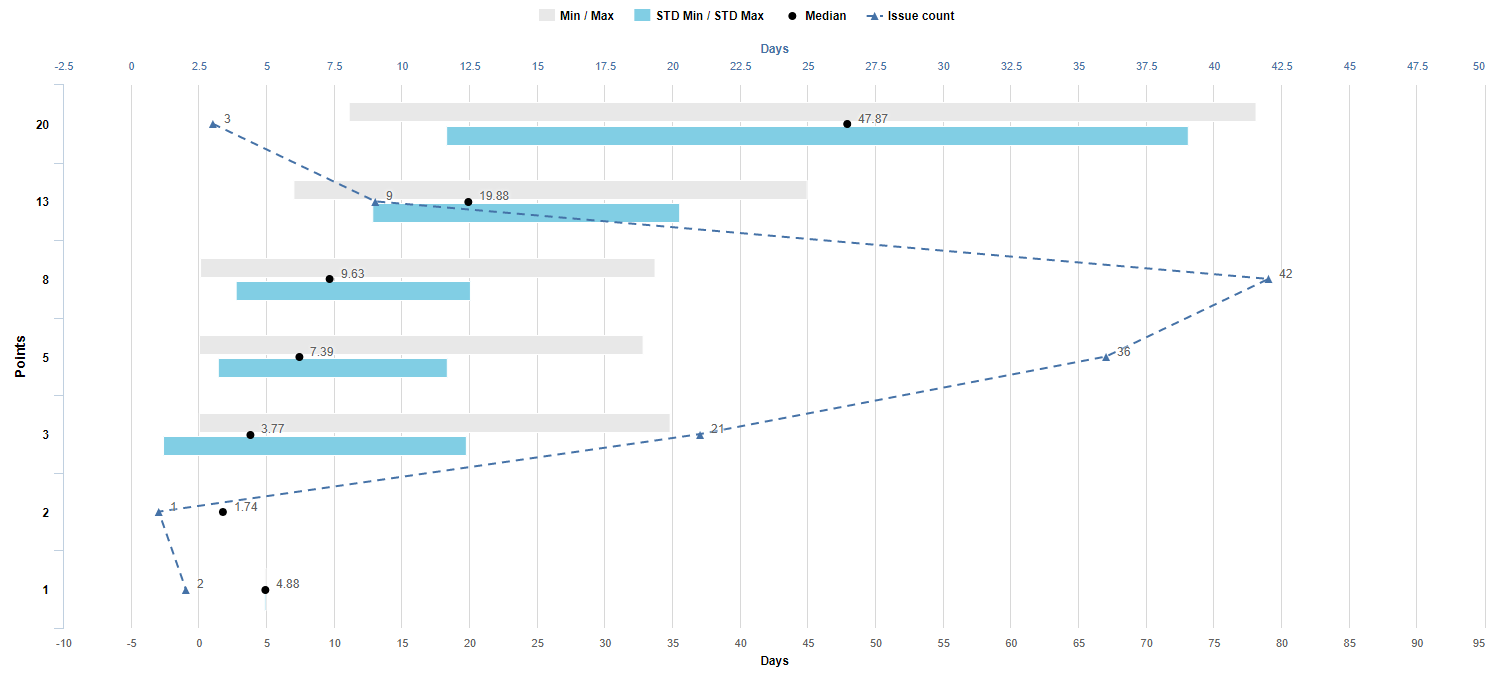
[Story Points] is a new dimension in rows. [Measures] is in columns. [Project], [Time], and [Transition Status] are in Pages.
Thanks for any help that can be provided.
– Malik Graves-Pryor